
1 那一夜,你伤害了我
今夜的雨下得凉快,小南睡得正香,突然收到远洋运维小周的电话:Hello, Are you OK? WAS有issue,快起来help me!

只见小南登陆WAS机,查看了机器日志、应用日志,终于定位了问题,登上WAS管理界面,一顿操作猛如虎,应用终于恢复了。但不记得这是第几次新人不懂WAS而向小南求救了。
第二天,小南向领导呈上《替换WAS表》,开始了一场浩荡的服务器之战。其文曰:
先弟修bug未半,而中道离职。今WAS已老,Springboot又新,此诚用Boot换WAS之秋也。
......
今当替换,临码涕零,不知所言。
所谓WAS,即IBM的WebSphere Application Server,是一种Java应用服务器。相对Tomcat等,会更重型,更复杂;更重要的是价格昂贵。得益于IBM及它一整套的企业开发套件,也还是有一定的市场占有率,特别是在传统行业里。
随着技术向前发展与之前轰轰烈烈的去IOE运动,用WAS的人越来越少了,许多新人更是完全没有接触过,又因其价格昂贵且不利于DevOps,我司决定要替换掉它。经讨论,代替它上场的就是现在红红火火的Springboot,原因众多,如开源免费、开箱即用、利于发布、容易运维等。
2 大刀阔斧还是小打小闹
硬件、软件同时替换,就必须谨慎小心,主要方案如下:
(1)硬件上从装有WAS机器的Linux转移到普通的Linux机器,但需要注意关键指标如处理器、内存、硬盘等。
(2)软件上从之前打成war包,现改为jar包,包结构完全改变,引入Springboot后,Spring容器和bean要对应调整、数据库池化也对应调整。原来WAS跑的是SOAP Webservice,现通过Springboot整合cxf-spring-boot-starter-jaxws实现。
(3)网络上依然是https协议,但以前WEB服务器为IHS,现在直接使用Springboot,证书需要重新生成和导入。客户端证书要先从IHS服务器的密钥文件导出,需要查看IBM官网资料。
关于https的内容可参考:HTTPS专题。
同时引入新的负载均衡器F5,且需要在上线当天更新DNS到新F5上。结构图如下:
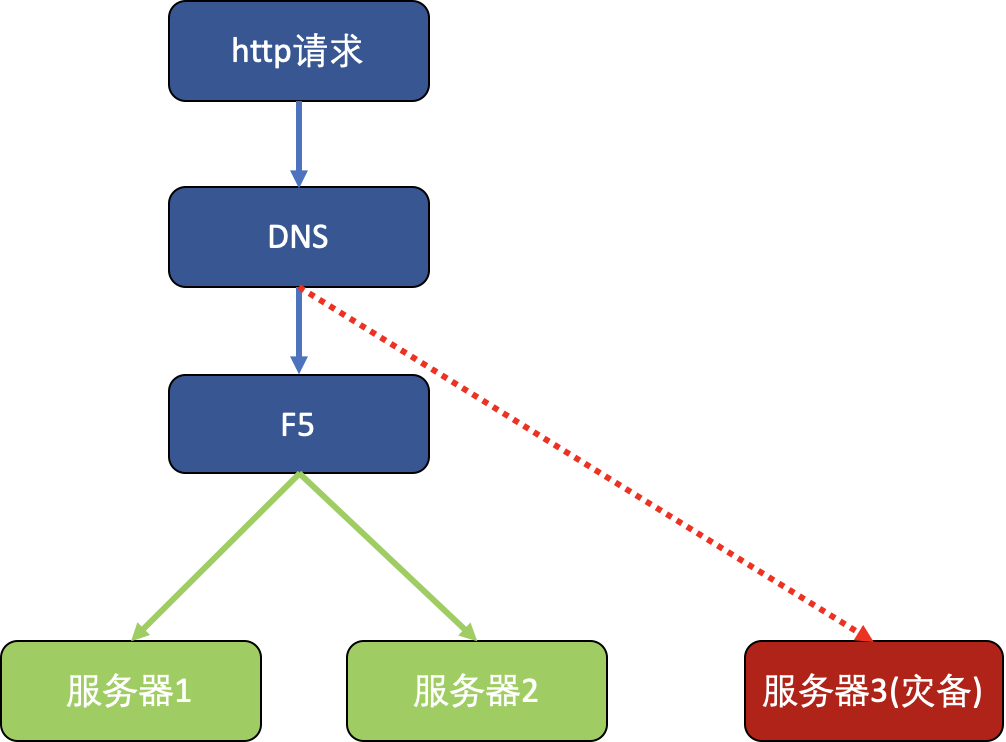
服务器1与服务器2在同一个数据中心,正常运行时处于工作状态。如果该数据中心发生灾难(如地震等),就会启用服务器3,并把DNS更新到灾备服务器的地址。
(4)发布上由手工发布改为Ansible发布,可减少人力和错误风险。
(5)监测上有日志监控,但Springboot日志文件更少更集中,同时Springboot可整合Springboot Admin,可参考:用Springboot Admin监控你的微服务应用。
(6)UAT需要实现多环境部署,可通过maven实现。
3 测试
任何变更都有可能出错,都会引入风险。由墨菲定律可知,凡是可能出错的事就一定会出错。所以测试变得极为重要。在整个项目的测试中,功能测试和端到端测试都发现了问题,所以不要放过可以发现问题的机会,不然上了生产再出现,成本可太高了。
所谓君子不立危墙之下,让我们看看都怎么测试。
3.1 单元测试
单元测试在开发阶段就要完成,特别要关注测试覆盖率、圈复杂度等指标。可以使用Sonar、Findbugs等工具进行检测,可以参考下面的文章:
Maven整合JaCoCo和Sonar,看看你的测试写够了没
Docker搭建代码检测平台SonarQube并检测maven项目
3.2 功能测试
根据业务定义测试场景,尽量全面。特别是基线用例,必须覆盖。可以增加异常场景的用例,保证服务不会受影响,依然保持可用;错误场景是否有合理的告警,也是很关键的。
3.3 性能与压力测试
测试出关键性能指标,看是否能满足现在的生产需求,要特别注意测试环境与生产环境的差异有多大,测试报告有多大的参考价值。压力测试可以分为两类,大请求和高并发,大请求是一个请求数据量很大,高并发是指多个请求同时产生。
3.4 端到端测试
联系其它相关团队(客户端,即请求端)进行端到端的测试,在测试环境发送正式的请求。
4 上线
领导说过,生产是最好的测试环境,哈哈,测试差不多了,就该上生产了。
但上生产不是那么容易的事,首先要确保发布的这个downtime没有客户端发请求过来,需要和其它团队约定好时间停服。更重要的是,因为希望只是自己做变更,不能要求别人做变更,所以域名不能变,就需要找网络团队更新DNS到新服务上。
为了缩短停服时间,提前把Springboot部署到新服务器上,并把新服务器配置在新的F5上,发布那天直接更新DNS到F5上即可。DNS更新完成后,找客户端发送请求进行测试,没有问题即大功告成了!
虽然已经成功上线,但旧服务器还是要并行一段时间,万一新服务出问题,紧急情况难以修复,还可以回滚。
5 还能再做什么
虽然已经上线了,但还是有更多东西可以做的。
文档:人的记忆都是不可靠的,同时也要减少人员流动的风险,需要通过文档把相关内容记录下来,并分享到整个团队。主要内容有开发过程、架构原理、生产环境运维指南、测试环境使用、关键知识索引等。
灾备测试:做了灾备,但并没有测试。还好公司要求定期要做灾备测试,到时可以覆盖,现在没做会增大风险。
ELK:日志收集没有统一到日志平台,需要登陆到指定机器查看。幸好所用的机器不多。
Metric指标:可以收集JVM内存、CPU、GC等信息,以便定位问题,可以展示到Grafana上。
OpenTracing:可以记录每次请求的详细情况。可参考:实例讲解Springboot整合OpenTracing分布式链路追踪系统(Jaeger和Zipkin)
REST/RPC改造:现在的服务为XML格式的WebService,可改造为RESTful+Json或gRPC。
最后,并不是引入新技术就是好的,有时候需要KISS(Keep it simple and stupid),简单能用就是好的,不要想着搞些大新闻,这样有时间还是很naive的。
6 总结
小南独立完成了这次改造后,去了趟黄山修练内功,修仙成果如下:黄山徽州五日行-最美风景与攻略献给你。
回来后,又开始新的征程,这次要改造整个旧系统:System Entire Rebuild (SER)。后续如何,请听下回粪解。