# 被Spring坑了一把,查看源码终于解决了DataFlow部署K8s应用的问题
# 1 前言
基于各种原因,团队的Kubernetes被加了限制,必须在特定的Node才可以部署。而之前没有指定,所以Spring Cloud Data Flow在跑Task时失败了,无法创建Pod。按照Spring官方文档配置也一直没用,后面查看源码、修改源码增加日志后终于解决了。
# 2 配置无法生效
在自己定义yaml文件,并通过kubectl apply部署时,所添加的限制节点的内容是这样的:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
containers:
- name: php-apache
image: 'pkslow/hpa-example:latest'
ports:
- containerPort: 80
protocol: TCP
resources:
requests:
cpu: 200m
imagePullPolicy: IfNotPresent
这样设置是可以成功部署的。
修改Data Flow的配置如下:
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"
通过Spring Cloud Data Flow发布Task,报错如下:
Pods in namespace pkslow can only map to specific nodes, status=Failure
查看官网,按照官方的格式 (opens new window)修改配置:
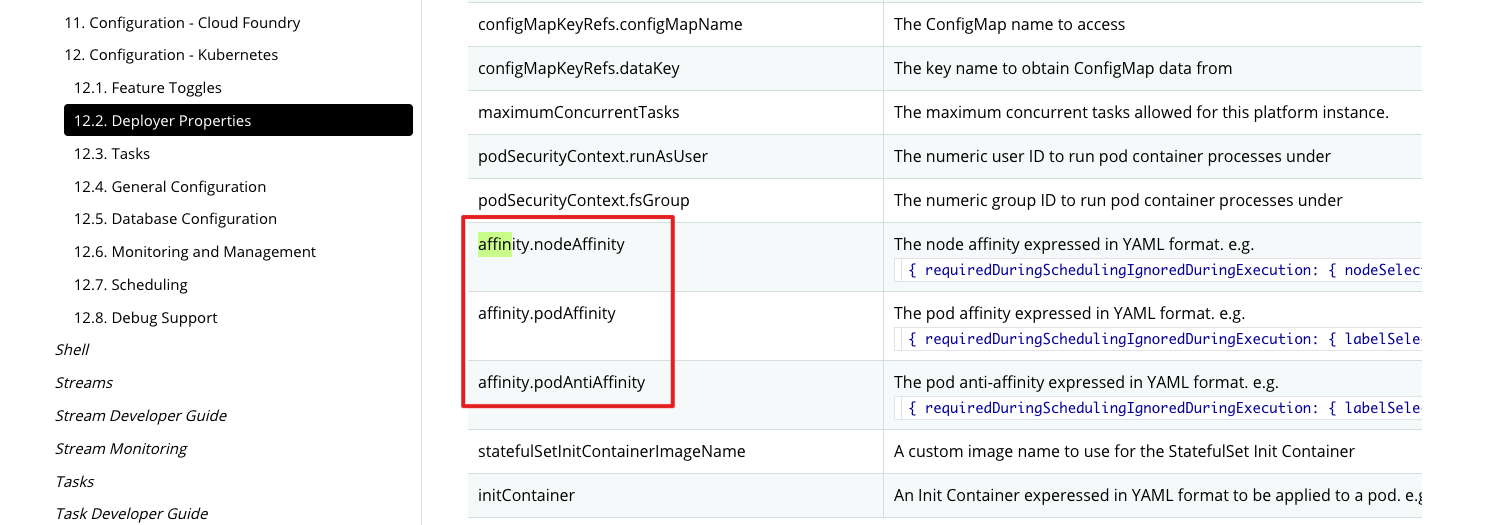
修改如下:
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
affinity:
nodeAffinity: { requiredDuringSchedulingIgnoredDuringExecution: { nodeSelectorTerms: [ { matchExpressions: [ { key: 'beta.kubernetes.io/os', operator: 'In', values: [ 'linux']}]}]}}
依旧报错。改成affinity.nodeAffinity=xxx,还是报错。加引号,也没用。
查看日志,也没有太多信息。
折腾了许久,也没太大进展。于是就查看源码了。
# 3 查看源码
# 3.1 源码下载
下载了Spring Cloud Data Flow (opens new window)的源码,看了一下,没有多大用处,最终发布到Kubernetes是通过Spring Cloud Deployer Kubernetes来发布的,于是又下载了它的源码 (opens new window)。要注意不要下载错了版本,我们用的是2.4.0版本。或者直接下载所有,然后切换到对应分支:
$ git clone https://github.com/spring-cloud/spring-cloud-deployer-kubernetes.git
Cloning into 'spring-cloud-deployer-kubernetes'...
remote: Enumerating objects: 65, done.
remote: Counting objects: 100% (65/65), done.
remote: Compressing objects: 100% (46/46), done.
remote: Total 4201 (delta 26), reused 42 (delta 8), pack-reused 4136
Receiving objects: 100% (4201/4201), 738.79 KiB | 936.00 KiB/s, done.
Resolving deltas: 100% (1478/1478), done.
$ cd spring-cloud-deployer-kubernetes/
$ git branch
* master
$ git checkout 2.4.0
Branch '2.4.0' set up to track remote branch '2.4.0' from 'origin'.
Switched to a new branch '2.4.0'
$ git branch
* 2.4.0
master
先build一下,确保成功:
$ mvn clean install -DskipTests
# 3.2 添加日志
查看源码,也看不出为何配置没有生效,于是在关键点打些日志出来看看。找到发布Task的入口:
KubernetesTaskLauncher#launch(AppDeploymentRequest)
即类KubernetesTaskLauncher的launch方法。开始追踪创建Kubernetes Pod的过程。
KubernetesTaskLauncher#launch(AppDeploymentRequest)
KubernetesTaskLauncher#launch(String, AppDeploymentRequest)
AbstractKubernetesDeployer#createPodSpec
DeploymentPropertiesResolver#getAffinityRules
然后在整个调用链增加日志打印,注意日志要加上特殊字符串,增加识别性,如:
logger.info("***pkslow log***:" + affinity.toString());
追加了日志后,重新build包,替换掉Data Flow引入的jar包,重新发布即可测试。
通过新加的日志,发现设置的Properties一直就是没有生效的,但为何没生效尚未得知。
# 4 修改源码
折腾了一圈还是没解决,但项目又要急着使用,于是想了个办法,先修改源码,自己根据属性使其生效:
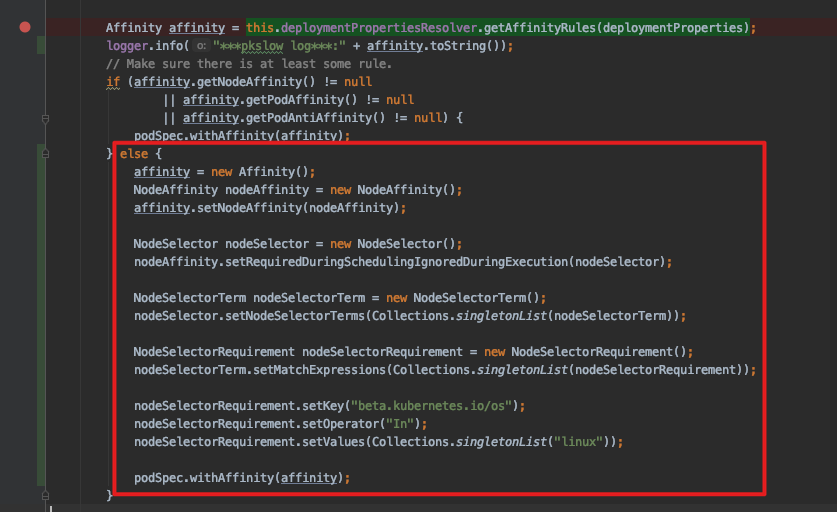
如果没有读取到Affinity,就自己生成一个。
重新打包、替换、部署后,不再报错,能正常执行Task了。
# 5 最终解决
之前的方案只是暂时解决,并不是一个好的办法,还是要搞清楚为何配置没有生效。于是再次查看源码。在查看类KubernetesDeployerProperties的时候,发现了一点端倪:

这里的字段是没有Affinity的。
另外,从测试用例入手(这是一个很好的思维,测试用例能告诉你很多信息),看到了DataFlow配置用例,如下:
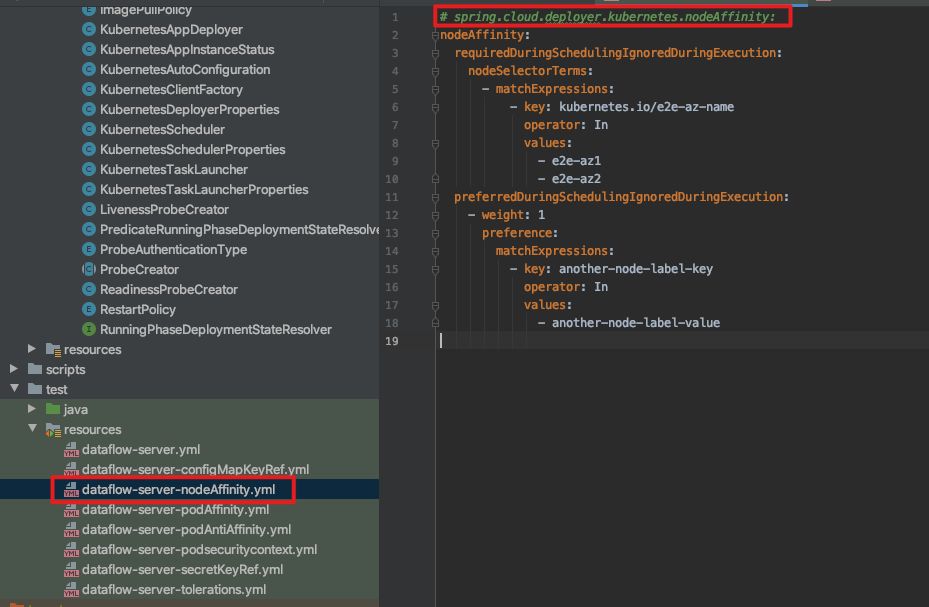
所以,应该是不用配置前缀Affinity的,修改后配置如下:
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
nodeAffinity: { requiredDuringSchedulingIgnoredDuringExecution: { nodeSelectorTerms: [ { matchExpressions: [ { key: 'beta.kubernetes.io/os', operator: 'In', values: [ 'linux']}]}]}}
重新部署后,可以了!!!
# 6 总结
这一次确实是被Spring坑了一把,没有明确给出配置的示例,然后官方文档给的提示也是极其误导。一开始很难想到是不用前缀Affinity的,因为Kubernetes的标准配置是有的,而Spring的官方文档提示也是有的。实在太坑了!
还好,通过查看源码及调试,终于解决了这个问题。