# 把Spring Cloud Data Flow部署在Kubernetes上,再跑个任务试试
# 前言
Spring Cloud Data Flow在本地跑得好好的,为什么要部署在Kubernetes上呢?主要是因为Kubernetes能提供更灵活的微服务管理;在集群上跑,会更安全稳定、更合理利用物理资源。
Spring Cloud Data Flow入门简介请参考:Spring Cloud Data Flow初体验,以Local模式运行 (opens new window)
# 2 部署Data Flow到Kubernetes
以简单为原则,我们依然是基于Batch任务,不部署与Stream相关的组件。
# 2.1 下载GitHub代码
我们要基于官方提供的部署代码进行修改,先把官方代码clone下来:
$ git clone https://github.com/spring-cloud/spring-cloud-dataflow.git
我们切换到最新稳定版本的代码版本:
$ git checkout v2.5.3.RELEASE
# 2.2 创建权限账号
为了让Data Flow Server有权限来跑任务,能在Kubernetes管理资源,如新建Pod等,所以要创建对应的权限账号。这部分代码与源码一致,不需要修改:
(1)server-roles.yaml
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: scdf-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "replicationcontrollers", "persistentvolumeclaims"]
verbs: ["get", "list", "watch", "create", "delete", "update"]
- apiGroups: [""]
resources: ["configmaps", "secrets", "pods/log"]
verbs: ["get", "list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets", "deployments", "replicasets"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
- apiGroups: ["extensions"]
resources: ["deployments", "replicasets"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["create", "delete", "get", "list", "watch", "update", "patch"]
(2)server-rolebinding.yaml
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: scdf-rb
subjects:
- kind: ServiceAccount
name: scdf-sa
roleRef:
kind: Role
name: scdf-role
apiGroup: rbac.authorization.k8s.io
(3)service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: scdf-sa
执行以下命令,创建对应账号:
$ kubectl create -f src/kubernetes/server/server-roles.yaml
$ kubectl create -f src/kubernetes/server/server-rolebinding.yaml
$ kubectl create -f src/kubernetes/server/service-account.yaml
执行完成后,可以检查一下:
$ kubectl get role
NAME AGE
scdf-role 119m
$ kubectl get rolebinding
NAME AGE
scdf-rb 117m
$ kubectl get serviceAccount
NAME SECRETS AGE
default 1 27d
scdf-sa 1 117m
# 2.3 部署MySQL
可以选择其它数据库,如果本来就有数据库,可以不用部署,在部署Server的时候改一下配置就好了。这里跟着官方的Guide来。为了保证部署不会因为镜像下载问题而失败,我提前下载了镜像:
$ docker pull mysql:5.7.25
MySQL的yaml文件也不需要修改,直接执行以下命令即可:
$ kubectl create -f src/kubernetes/mysql/
执行完后检查一下:
$ kubectl get Secret
NAME TYPE DATA AGE
default-token-jhgfp kubernetes.io/service-account-token 3 27d
mysql Opaque 2 98m
scdf-sa-token-wmgk6 kubernetes.io/service-account-token 3 123m
$ kubectl get PersistentVolumeClaim
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql Bound pvc-e95b495a-bea5-40ee-9606-dab8d9b0d65c 8Gi RWO hostpath 98m
$ kubectl get Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
mysql 1/1 1 1 98m
$ kubectl get Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.98.243.130 <none> 3306/TCP 98m
# 2.4 部署Data Flow Server
# 2.4.1 修改配置文件server-config.yaml
删除掉不用的配置,主要是Prometheus和Grafana的配置,结果如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: scdf-server
labels:
app: scdf-server
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"
# 2.4.2 修改server-svc.yaml
因为我是本地运行的Kubernetes,所以把Service类型从LoadBalancer改为NodePort,并配置端口为30093。
kind: Service
apiVersion: v1
metadata:
name: scdf-server
labels:
app: scdf-server
spring-deployment-id: scdf
spec:
# If you are running k8s on a local dev box or using minikube, you can use type NodePort instead
type: NodePort
ports:
- port: 80
name: scdf-server
nodePort: 30093
selector:
app: scdf-server
# 2.4.3 修改server-deployment.yaml
主要把Stream相关的去掉,如SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI配置项:
apiVersion: apps/v1
kind: Deployment
metadata:
name: scdf-server
labels:
app: scdf-server
spec:
selector:
matchLabels:
app: scdf-server
replicas: 1
template:
metadata:
labels:
app: scdf-server
spec:
containers:
- name: scdf-server
image: springcloud/spring-cloud-dataflow-server:2.5.3.RELEASE
imagePullPolicy: IfNotPresent
volumeMounts:
- name: database
mountPath: /etc/secrets/database
readOnly: true
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /management/health
port: 80
initialDelaySeconds: 45
readinessProbe:
httpGet:
path: /management/info
port: 80
initialDelaySeconds: 45
resources:
limits:
cpu: 1.0
memory: 2048Mi
requests:
cpu: 0.5
memory: 1024Mi
env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: "metadata.namespace"
- name: SERVER_PORT
value: '80'
- name: SPRING_CLOUD_CONFIG_ENABLED
value: 'false'
- name: SPRING_CLOUD_DATAFLOW_FEATURES_ANALYTICS_ENABLED
value: 'true'
- name: SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED
value: 'true'
- name: SPRING_CLOUD_KUBERNETES_SECRETS_ENABLE_API
value: 'true'
- name: SPRING_CLOUD_KUBERNETES_SECRETS_PATHS
value: /etc/secrets
- name: SPRING_CLOUD_KUBERNETES_CONFIG_NAME
value: scdf-server
- name: SPRING_CLOUD_DATAFLOW_SERVER_URI
value: 'http://${SCDF_SERVER_SERVICE_HOST}:${SCDF_SERVER_SERVICE_PORT}'
# Add Maven repo for metadata artifact resolution for all stream apps
- name: SPRING_APPLICATION_JSON
value: "{ \"maven\": { \"local-repository\": null, \"remote-repositories\": { \"repo1\": { \"url\": \"https://repo.spring.io/libs-snapshot\"} } } }"
initContainers:
- name: init-mysql-wait
image: busybox
command: ['sh', '-c', 'until nc -w3 -z mysql 3306; do echo waiting for mysql; sleep 3; done;']
serviceAccountName: scdf-sa
volumes:
- name: database
secret:
secretName: mysql
# 2.4.4 部署Server
完成文件修改后,就可以执行以下命令部署了:
# 提前下载镜像
$ docker pull springcloud/spring-cloud-dataflow-server:2.5.3.RELEASE
# 部署Data Flow Server
$ kubectl create -f src/kubernetes/server/server-config.yaml
$ kubectl create -f src/kubernetes/server/server-svc.yaml
$ kubectl create -f src/kubernetes/server/server-deployment.yaml
执行完成,没有错误就可以访问:http://localhost:30093/dashboard/

# 3 运行一个Task
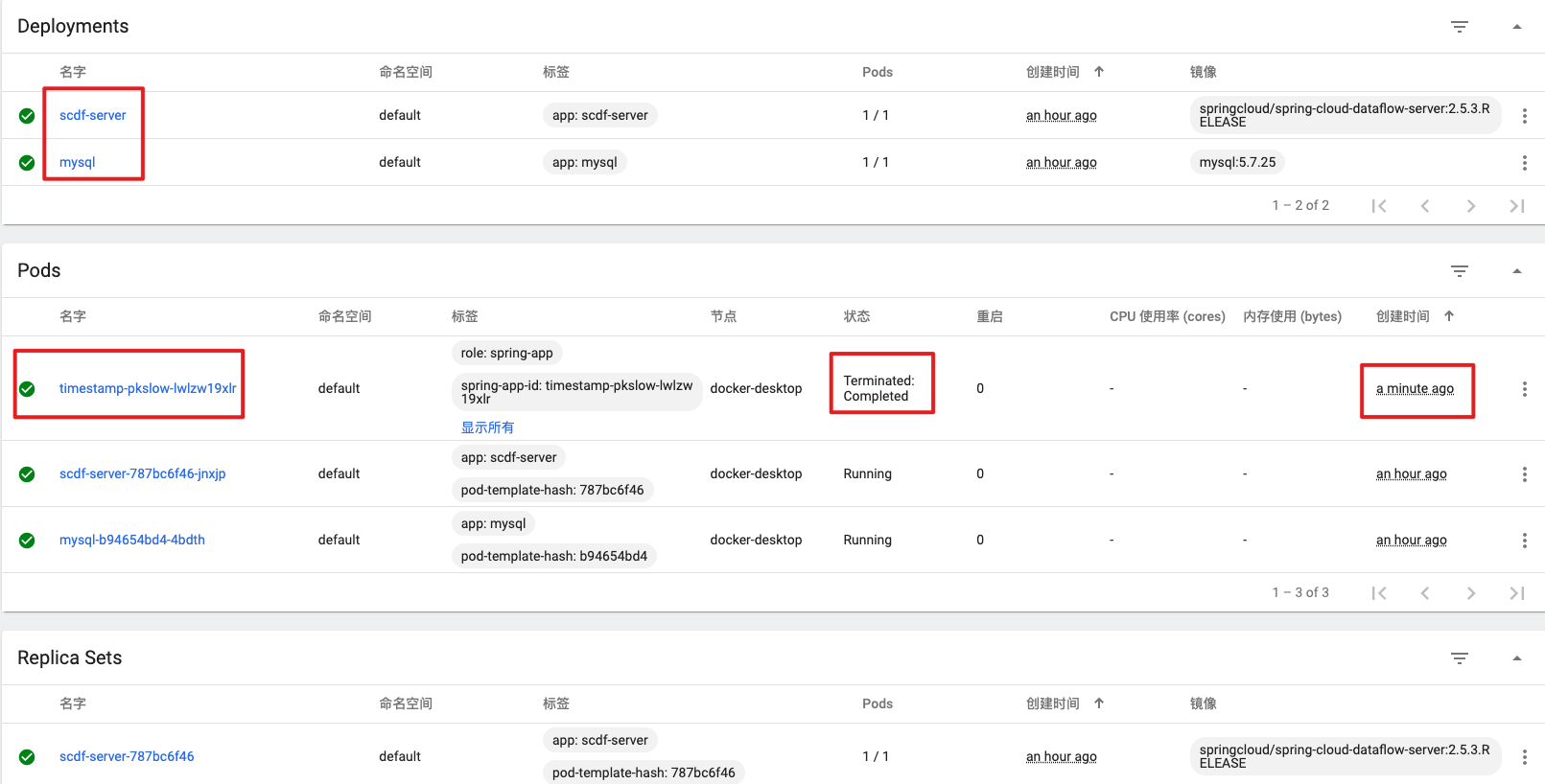
检验是否部署成功最简单的方式就是跑一个任务试试。还是按以前的步骤,先注册应用,再定义Task,然后执行。
我们依旧使用官方已经准备好的应用,但要注意这次我们选择是的Docker格式,而不是jar包了。


成功执行后,查看Kubernetes的Dashboard,能看到一个刚创建的Pod:
# 4 总结
本文通过一步步讲解,把Spring Cloud Data Flow成功部署在了Kubernetes上,并成功在Kubenetes上跑了一个任务,再也不再是Local本地单机模式了。