# InfluxDB入门及使用,一个优秀的时序数据库
# 1 前言
今天介绍一个优秀的时序数据库InfluxDB,后续我们将会使用到它。

# 2 InfluxDB简介
InfluxDB (opens new window)可能许多人没听过,或者听过没用过。它是一个用于存储和分析时间序列的开源数据库。作为时序数据库的佼佼者,得到了越来越广泛的应用。它在DB-Engines (opens new window)的排名中也是第一位,如下图所示:
![]()
InfluxDB有使用方便、查询灵活、类SQL查询语句、读写高效的特点。作为时序数据库,用于运维监控是十分合适的,能看到应用某个指标的实时状态和历史变化曲线,如内存使用情况、访问量等。
# 3 安装InfluxDB
各种系统的安装指导可以参考官方文档的安装指导 (opens new window),包括Ubuntu、CentOS、MacOS等。我为了方便,就使用Docker的方式进行安装使用。
选择最新的稳定版本1.8.2,拉取镜像如下:
$ docker pull influxdb:1.8.2
启动InfluxbDB:
$ docker run -itd --name influxdb -p 8086:8086 influxdb:1.8.2
# 4 使用InfluxDB
InfluxDB安装完成后,我们有多种方式来连接和操作,如直接通过HTTP方式、influx命令行方式、代码方式等。
# 4.1 HTTP方式
显示数据库:直接浏览器访问http://localhost:8086/query?q=show%20databases
创建数据库:$ curl -G http://localhost:8086/query --data-urlencode "q=CREATE DATABASE pkslow"
# 4.2 influx命令行方式
通过命令docker exec -it influxdb influx进入:
$ docker exec -it influxdb influx
Connected to http://localhost:8086 version 1.8.2
InfluxDB shell version: 1.8.2
>
显示数据库:
> show databases
name: databases
name
----
_internal
创建数据库:
> create database pkslow
> show databases
name: databases
name
----
_internal
pkslow
切换数据库:
> use pkslow
Using database pkslow
插入数据:
INSERT visits,link=www.pkslow.com value=100
这里表示measurement为visits,即访问量,tab是link,值为100,即访问量为100。
我们插多几条数据,然后查询数据如下:
> SELECT link,value FROM visits
name: visits
time link value
---- ---- -----
1600533599397400984 www.pkslow.com 100
1600533687723121911 www.pkslow.com 200
1600533696503141291 www.pkslow.com 222
看这语句,是不是像极了SQL?
# 4.3 Java连接操作方式
添加依赖如下:
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>2.9</version>
</dependency>
代码及注释如下:
package com.pkslow.influxdb;
import org.influxdb.InfluxDB;
import org.influxdb.InfluxDBFactory;
import org.influxdb.dto.BatchPoints;
import org.influxdb.dto.Point;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
import java.util.concurrent.TimeUnit;
public class InfluxDBMain {
public static void main(String[] args) {
//创建连接
InfluxDB influxDB = InfluxDBFactory.connect("http://localhost:8086");
//创建数据1
Point point1 = Point.measurement("visits")
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.tag("link", "pkslow.com")
.addField("value", 300.0)
.build();
//创建数据2
Point point2 = Point.measurement("visits")
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.tag("link", "www.pkslow.com")
.addField("value", 333.0)
.build();
//创建批量数据
BatchPoints batchPoints = BatchPoints.database("pkslow")
.retentionPolicy("autogen")
.build();
batchPoints.point(point1);
batchPoints.point(point2);
//将数据写入数据库
influxDB.write(batchPoints);
//创建查询对象
Query query = new Query("Select * From visits", "pkslow");
//查询
QueryResult result = influxDB.query(query);
//打印查询结果
System.out.println(result);
}
}
通过客户端执行查询语句,数据确实已经写入到InfluxDB中了:
> SELECT link,value FROM visits
name: visits
time link value
---- ---- -----
1600533599397400984 www.pkslow.com 100
1600533687723121911 www.pkslow.com 200
1600533696503141291 www.pkslow.com 222
1600535130268000000 pkslow.com 300
1600535130268000000 www.pkslow.com 333
>
# 5 InfluxDB客户端
通过命令行查看和操作有时不太方便,幸好也有一些不错的客户端工具。
# 5.1 InfluxDB Studio
InfluxDB Studio (opens new window)这个客户端不错,但只有Windows版本,Mac版本因有许多问题,暂不提供。
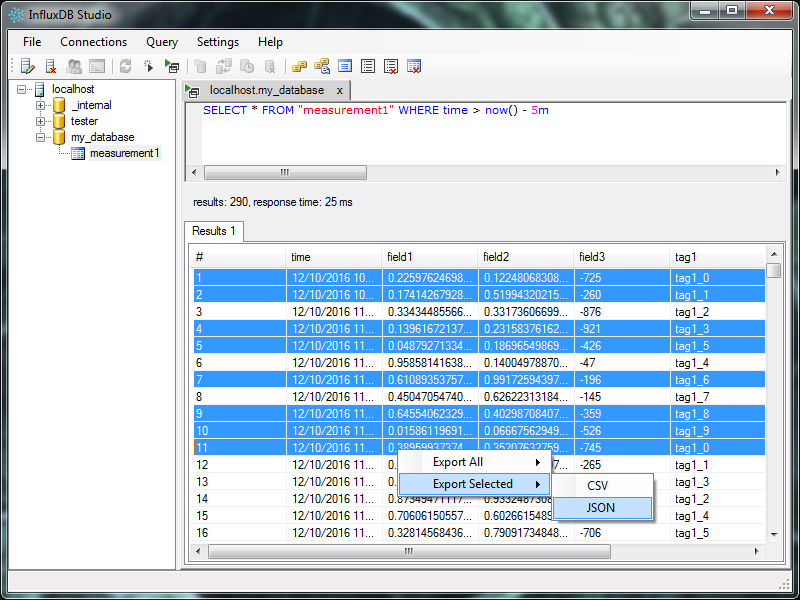
# 5.2 Influxdb-ui
InfluxDB-UI (opens new window)是基于React/Flux开发的,所以要使用它,需要将它部署在Web服务器上。不过,官方提供了一个已经部署好的网站(UI on S3 (opens new window))提供使用,并且保证不会保存任何用户信息。
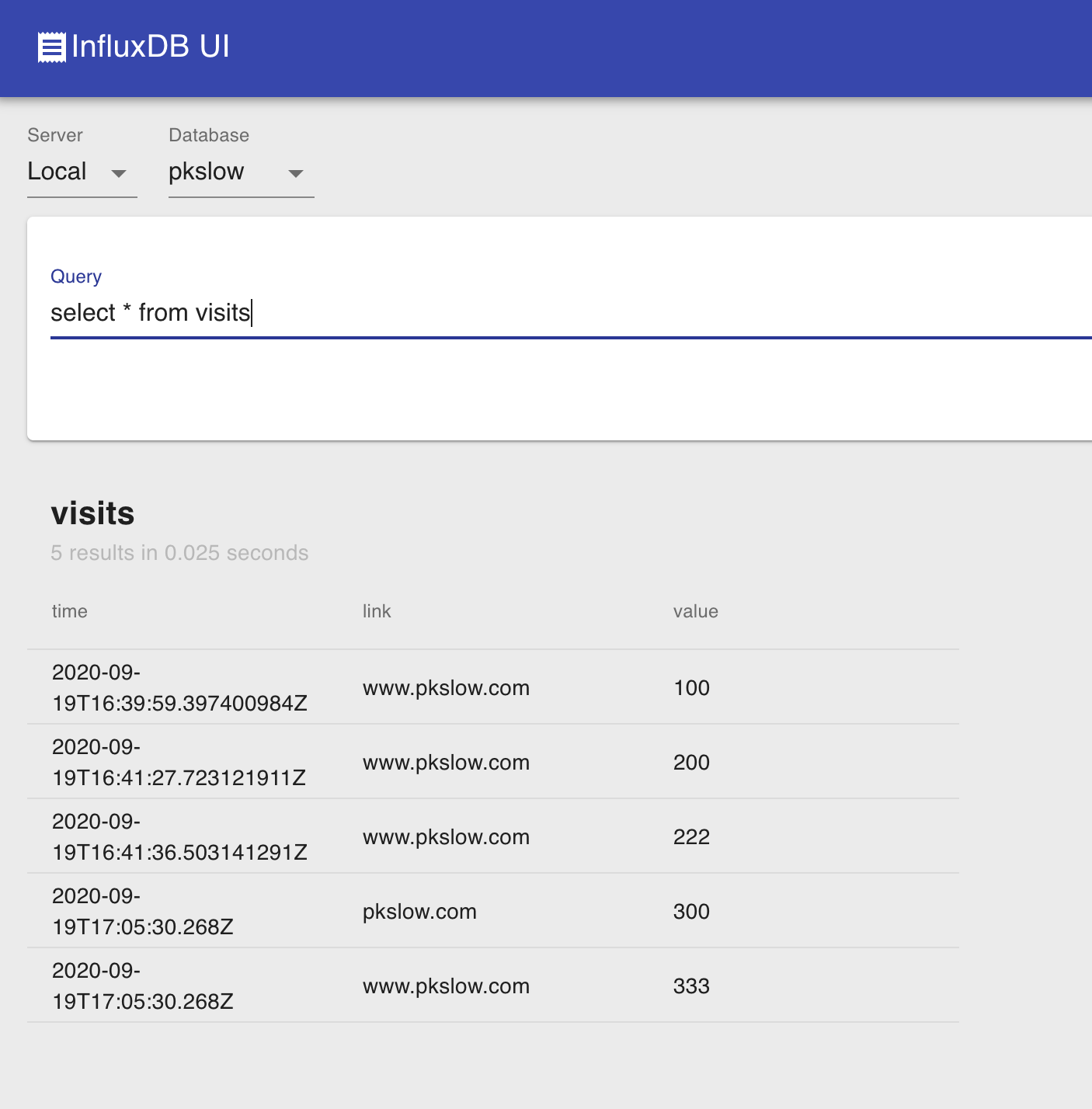
# 5.3 InfluxDB WorkBench
InfluxDB WorkBench (opens new window)是纯Java开发的,宣称只要能运行Java就可以使用。

# 6 总结
作为一个时序数据库,大家能想到什么应用场景呢?
项目代码在:https://github.com/LarryDpk/pkslow-samples
参考文档:
InfluxDB Docker Hub (opens new window)
InfluxDB中文文档 (opens new window)