# 让Apache Beam在GCP Cloud Dataflow上跑起来
# 简介
在文章《Apache Beam入门及Java SDK开发初体验 (opens new window)》中大概讲了Apapche Beam的简单概念和本地运行,本文将讲解如何把代码运行在GCP Cloud Dataflow上。
# 本地运行
通过maven命令来创建项目:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.37.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
上面会创建一个目录word-count-beam,里面是一个例子项目。做一些简单修改就可以使用了。
先build一次,保证依赖下载成功:
$ mvn clean package
通过IDEA本地运行一下,添加入参如下:
--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md
处理的文件是README.md,输出结果前缀为pkslow-beam-counts:

或者通过命令行来运行也可以:
mvn compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md"
# 在GCP Cloud Dataflow上运行
# 准备环境
要有对应的Service Account和key,当然还要有权限;
要打开对应的Service;
创建好对应的Bucket,上传要处理的文件。
# 运行
然后在本地执行命令如下:
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs://pkslow-dataflow/temp \
--project=pkslow --region=us-east1 \
--inputFile=gs://pkslow-dataflow/input/README.md --output=gs://pkslow-dataflow//pkslow-counts" \
-Pdataflow-runner
日志比较长,它大概做的事情就是把相关Jar包上传到temp目录下,因为执行的时候要引用。如:
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/apache/commons/commons-compress/1.8.1/commons-compress-1.8.1.jar to gs://pkslow-dataflow/temp/staging/commons-compress-1.8.1-X8oTZQP4bsxsth-9F7E31Z5WtFx6VJTmuP08q9Rpf70.jar
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/codehaus/jackson/jackson-mapper-asl/1.9.13/jackson-mapper-asl-1.9.13.jar to gs://pkslow-dataflow/temp/staging/jackson-mapper-asl-1.9.13-dOegenby7breKTEqWi68z6AZEovAIezjhW12GX6b4MI.jar
查看Bucket,确实有一堆jar包:

接着会创建dataflow jobs开始工作了。可以查看界面的Jobs如下:

点进去可以看到流程和更多细节:
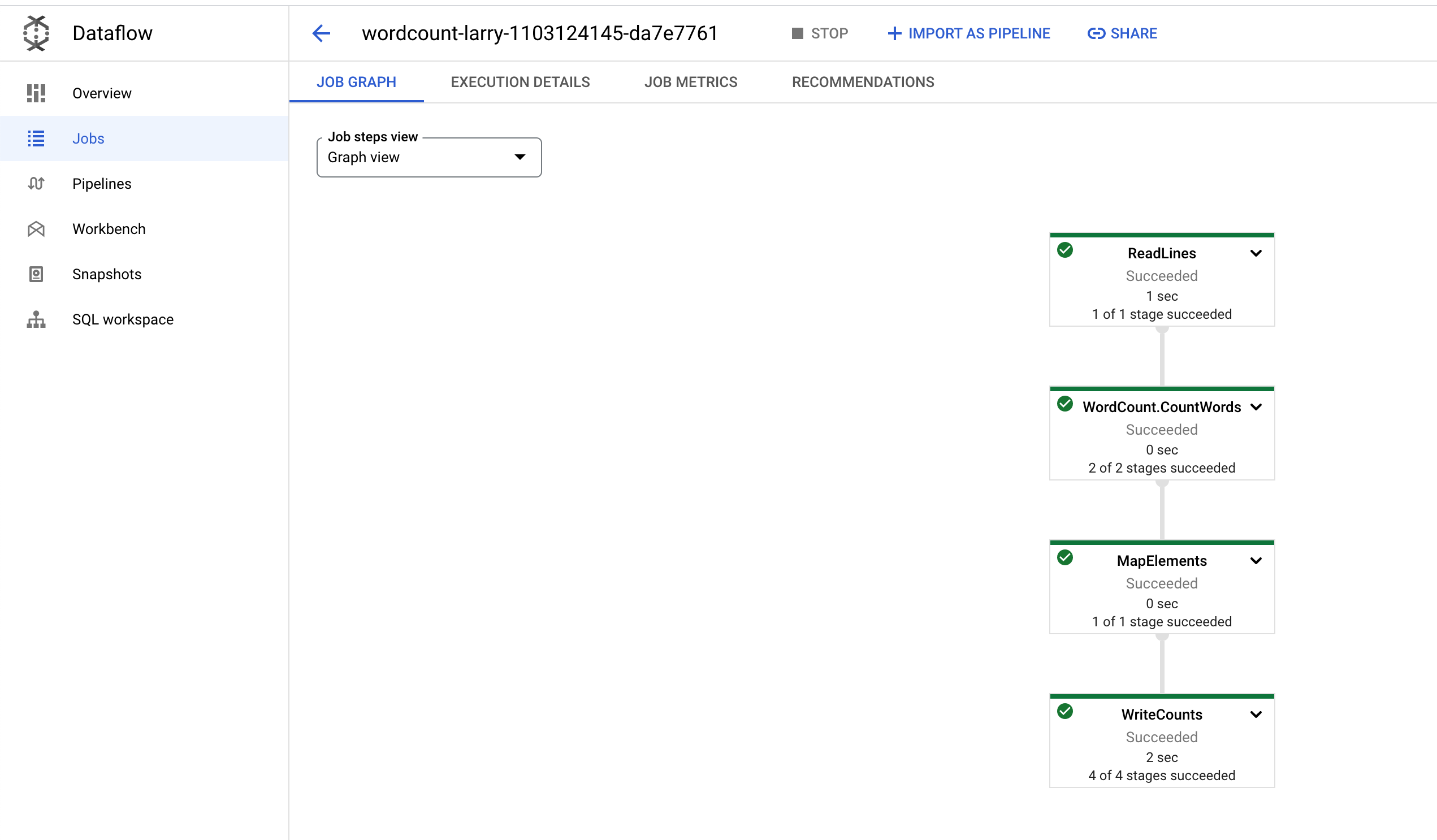
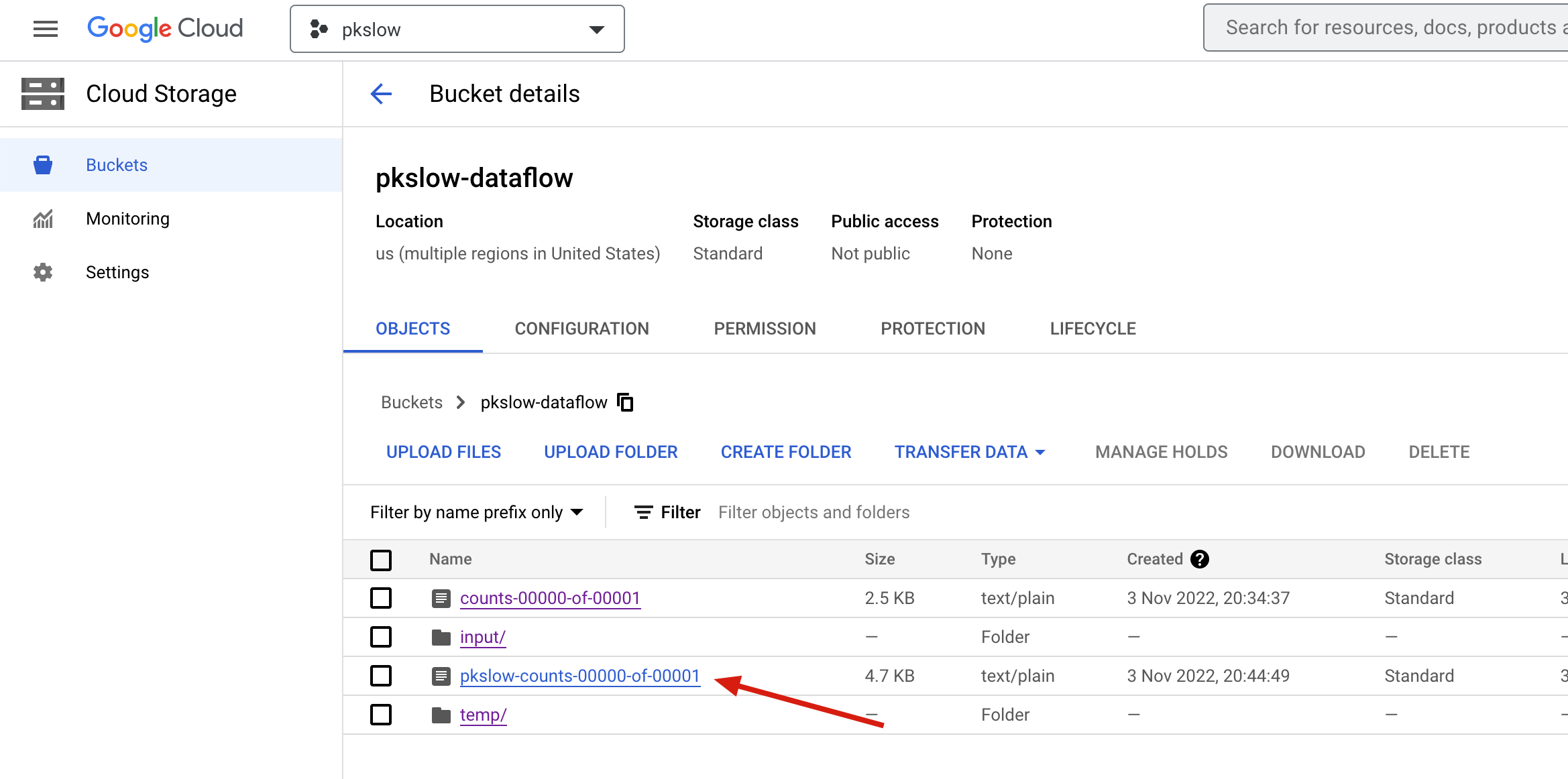
最后到Bucket查看结果也出来了:
# 代码
代码请看GitHub: https://github.com/LarryDpk/pkslow-samples
References: