# Apache Beam入门及Java SDK开发初体验
# 1 什么是Apache Beam
Apache Beam是一个开源的统一的大数据编程模型,它本身并不提供执行引擎,而是支持各种平台如GCP Dataflow、Spark、Flink等。通过Apache Beam来定义批处理或流处理,就可以放在各种执行引擎上运行了。
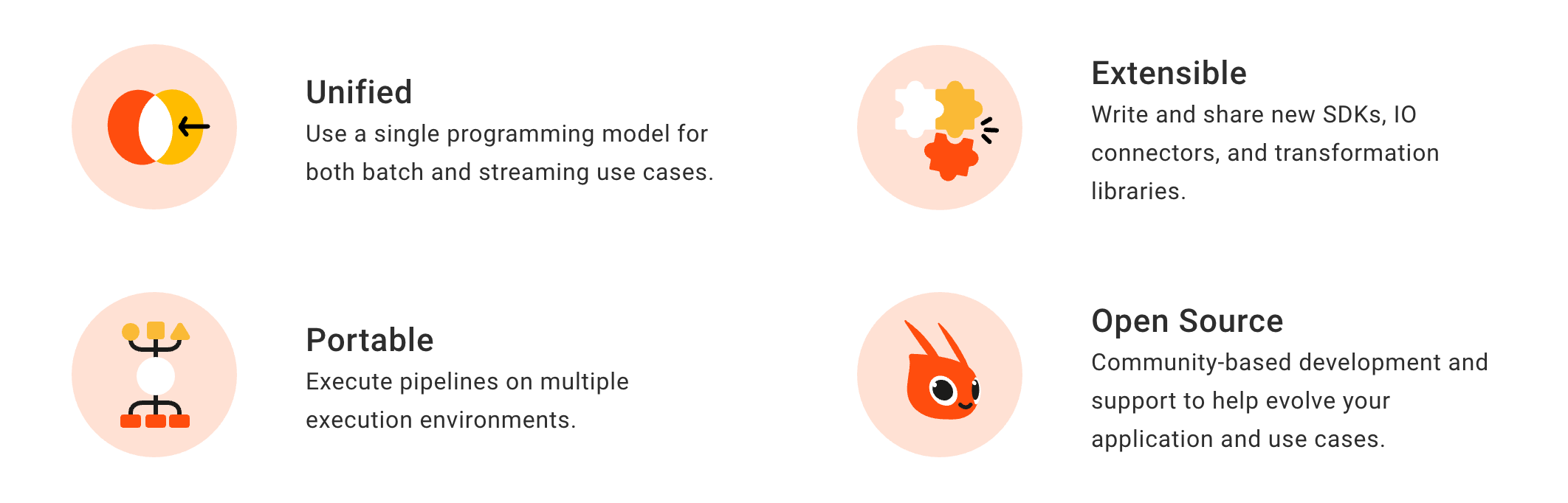
目前支持的SDK语言也很丰富,有Java、Python、Go等。
# 1.1 一些基础概念
PCollection:可理解为数据包,数据处理就是在对各种PCollection进行转换和处理。
PTransform:代表数据处理,用来定义数据是怎么被处理的,用来处理PCollection。
Pipeline:流水线,是由PTransform和PCollection组成的集合,可以理解为它定义了数据处理从源到目标的整个过程。
Runner:数据处理引擎。
一个最简单的Pipeline例子如下:

从数据库读数据为PCollection,经过转化成为另一个PCollection,然后写回到数据库中去。
可以有多个PTransform处理同一个PCollection:

一个PTransform也可以生成多个PCollection:

# 2 Java开发初体验
我们通过使用Java SDK来开发一个WordCount感受一下。
先引入必要的依赖,版本为2.32.0:
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>${beam.version}</version>
</dependency>
写Java主程序如下:
public class WordCountDirect {
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline pipeline = Pipeline.create(options);
PCollection<String> lines = pipeline.apply("read from file",
TextIO.read().from("pkslow.txt"));
PCollection<List<String>> wordList = lines.apply(MapElements.via(new SimpleFunction<String, List<String>>() {
@Override
public List<String> apply(String input) {
List<String> result = new ArrayList<>();
char[] chars = input.toCharArray();
for (char c:chars) {
result.add(String.valueOf(c));
}
return result;
}
}));
PCollection<String> words = wordList.apply(Flatten.iterables());
PCollection<KV<String, Long>> wordCount = words.apply(Count.perElement());
wordCount.apply(MapElements.via(new SimpleFunction<KV<String, Long>, String>() {
@Override
public String apply(KV<String, Long> count) {
return String.format("%s : %s", count.getKey(), count.getValue());
}
})).apply(TextIO.write().to("word-count-result"));
pipeline.run().waitUntilFinish();
}
}
直接运行,默认是通过DirectRunner来执行的,即在本地即可执行,不用搭建。非常方便开发和测试Pipeline。
整个程序大概流程是:
从pkslow.txt文件里读取所有行,然后将每一行拆分为多个字符,计算每个字符出现的次数,输出到文件中word-count-result。
pkslow.txt文件内容如下:
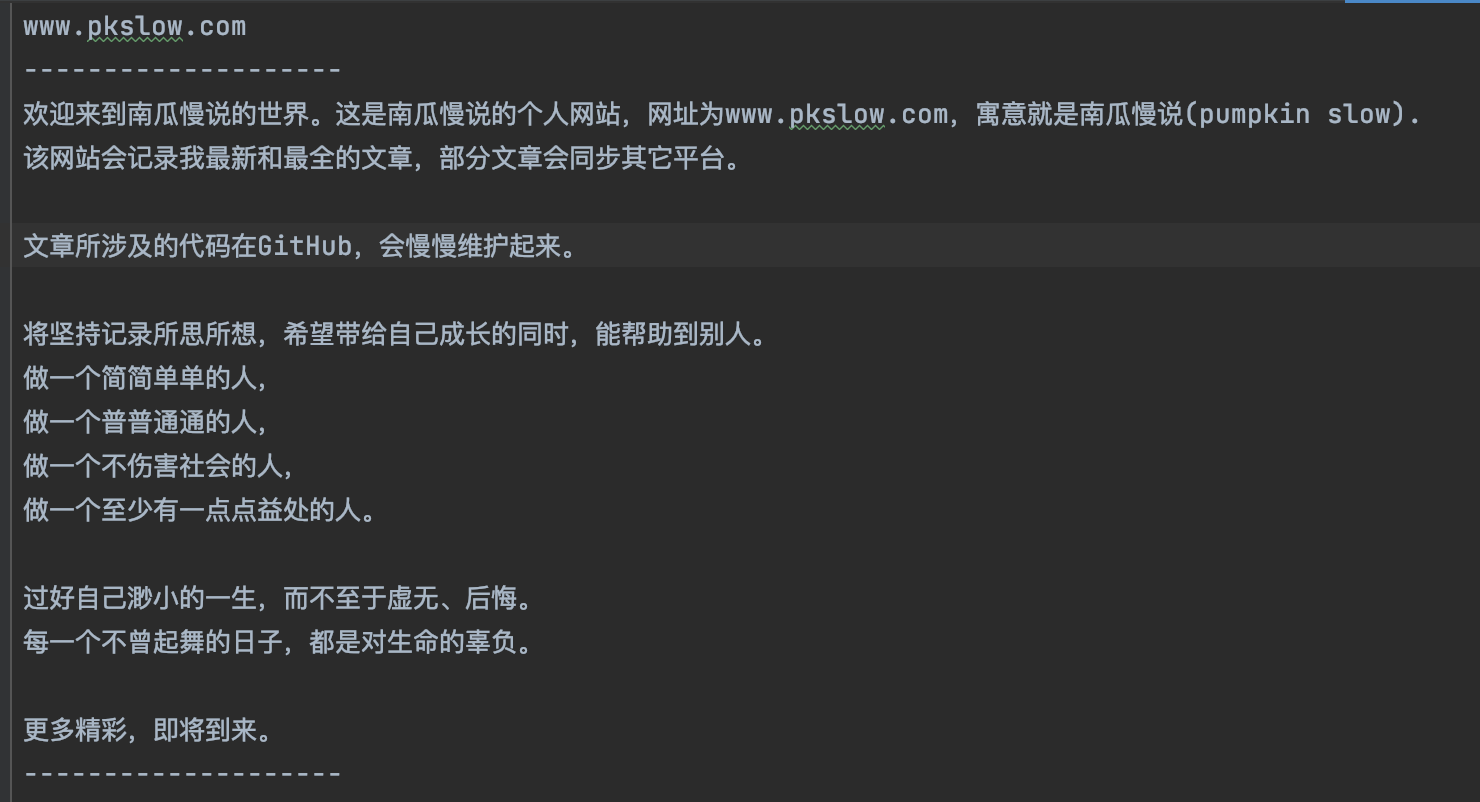
执行后的结果文件如下所示:

# 3 总结
简单体验了一下,基于Beam的模型开发还是很简单,很好理解的。但它在各种平台上的执行效率如何,就还需要深挖了。
代码请查看:https://github.com/LarryDpk/pkslow-samples
Reference:
Apache Beam Java SDK Quickstart (opens new window)
Design Your Pipeline (opens new window)