# Google Cloud Platform tutorial
# Start Free Trial
GCP provides $300 for free trial, I will show how to apply for it.
Go to cloud.google.com and click Get started for free:
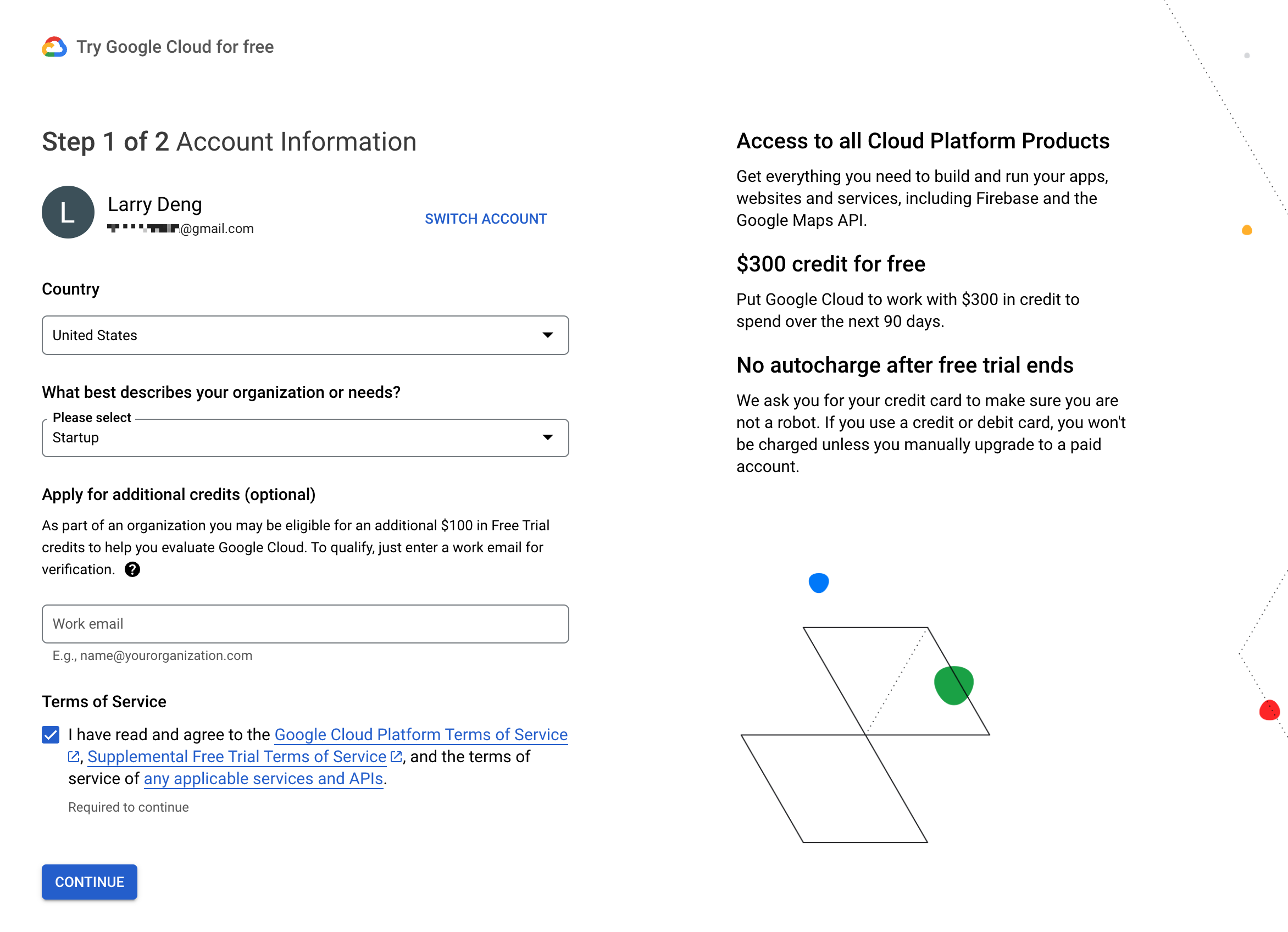
Set basic info:
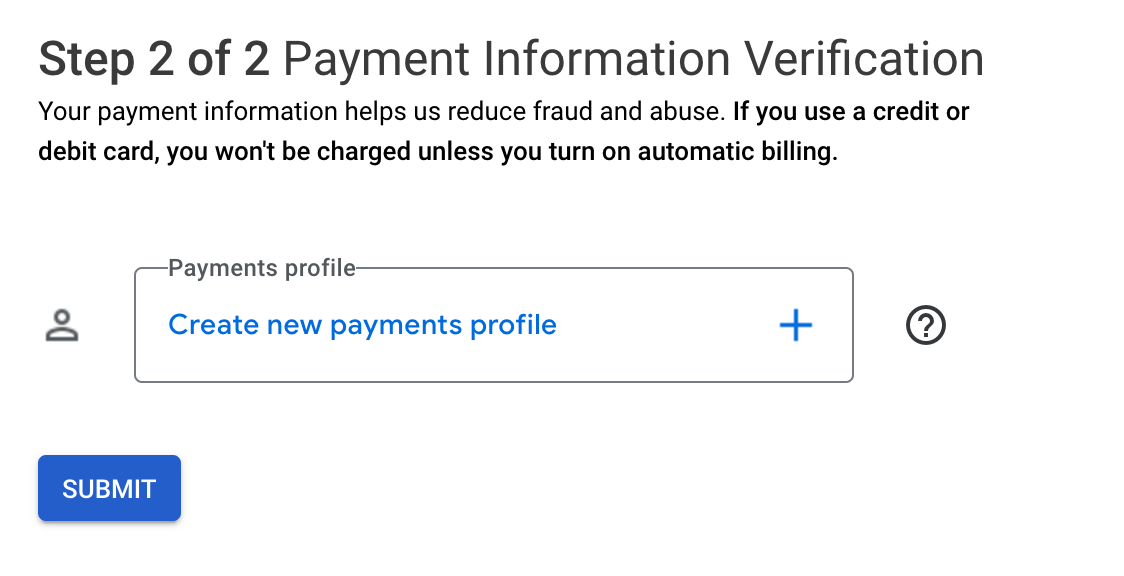
Add payment info:

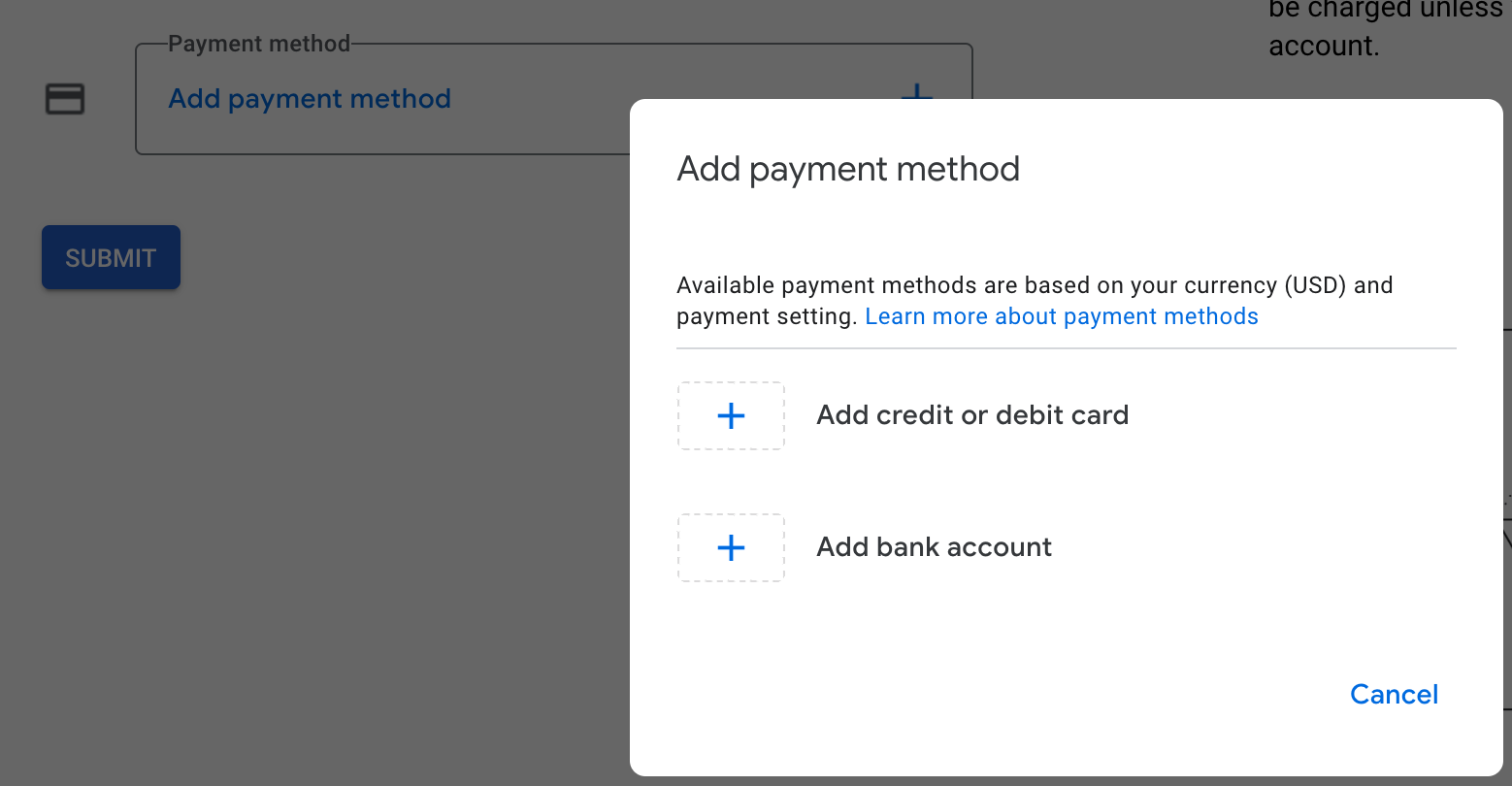
Add a visa credit card:
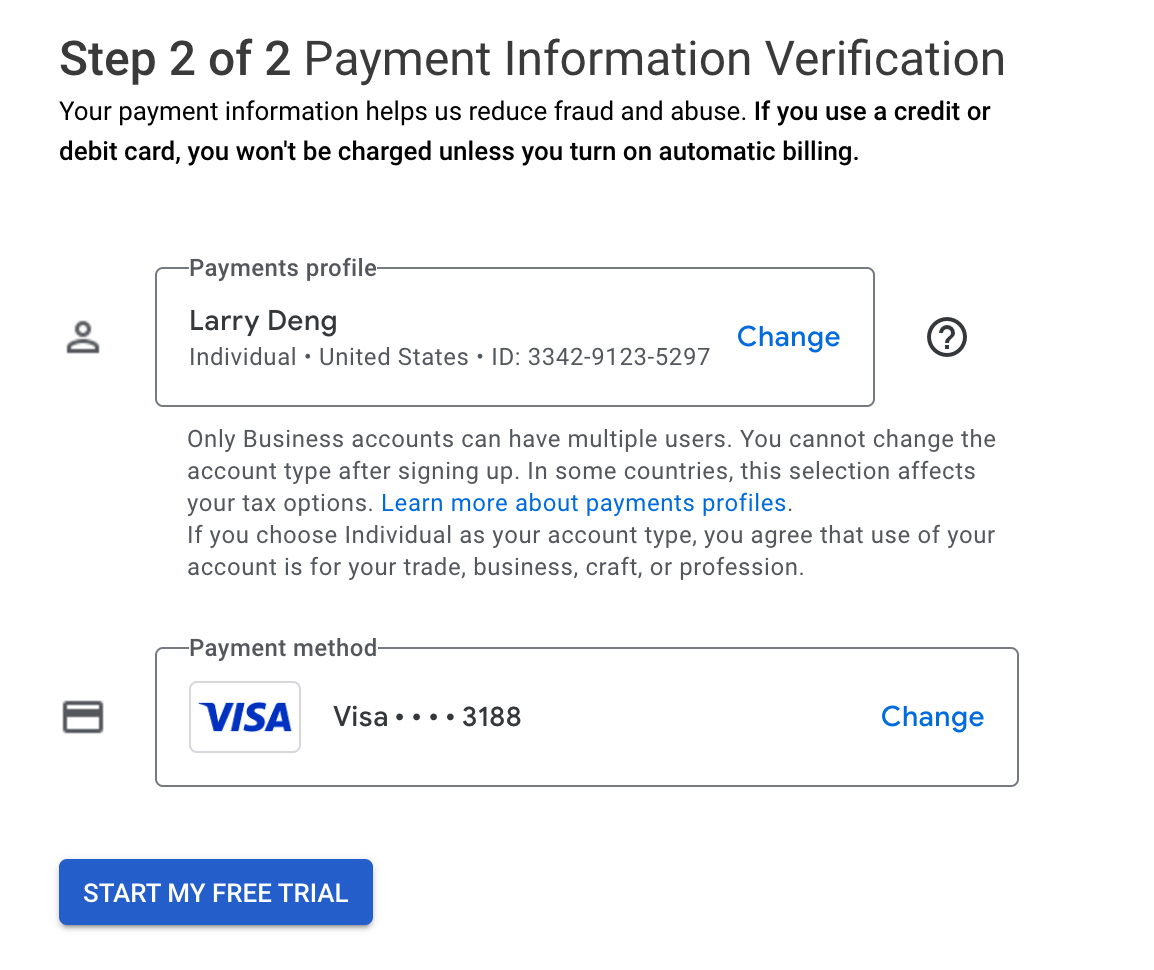
After a few seconds, the account is ready to use:
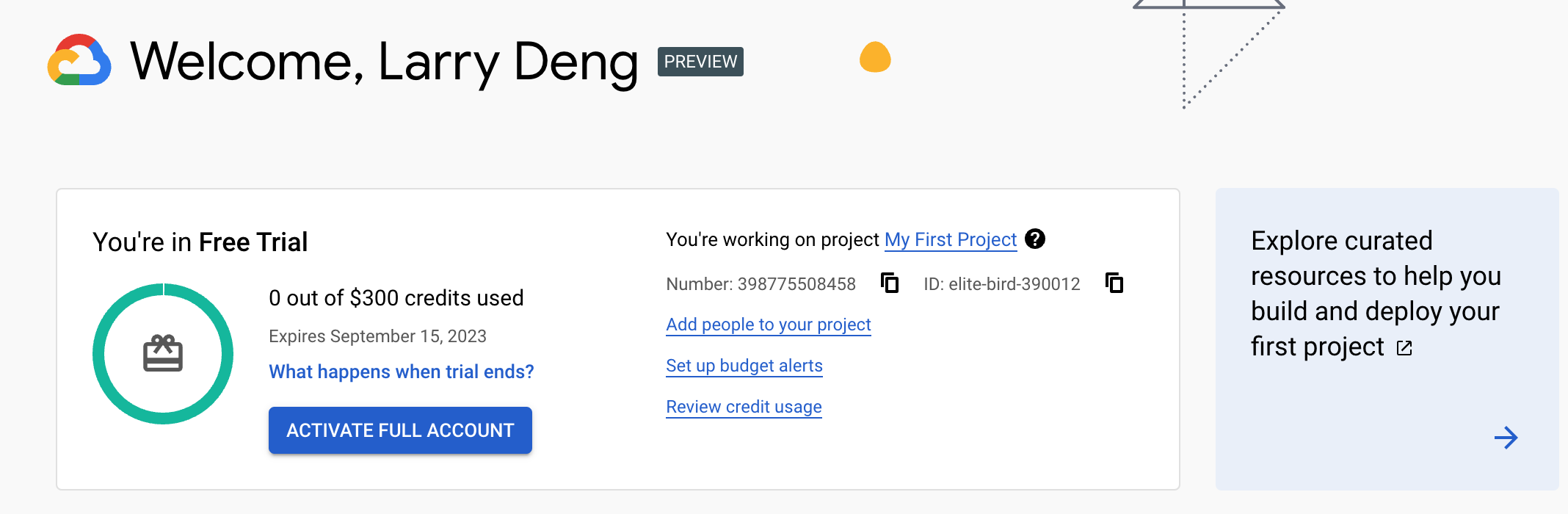
# create a new project
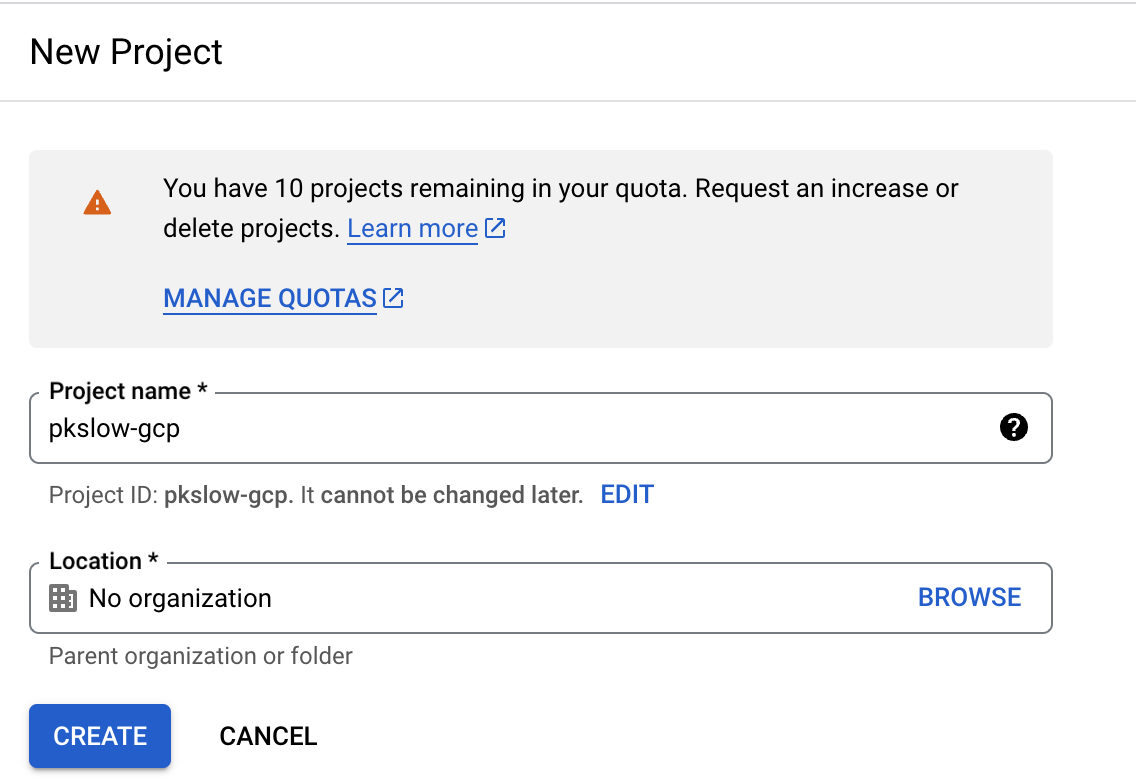
NEW PROJECT to create a new project:

Input the name:
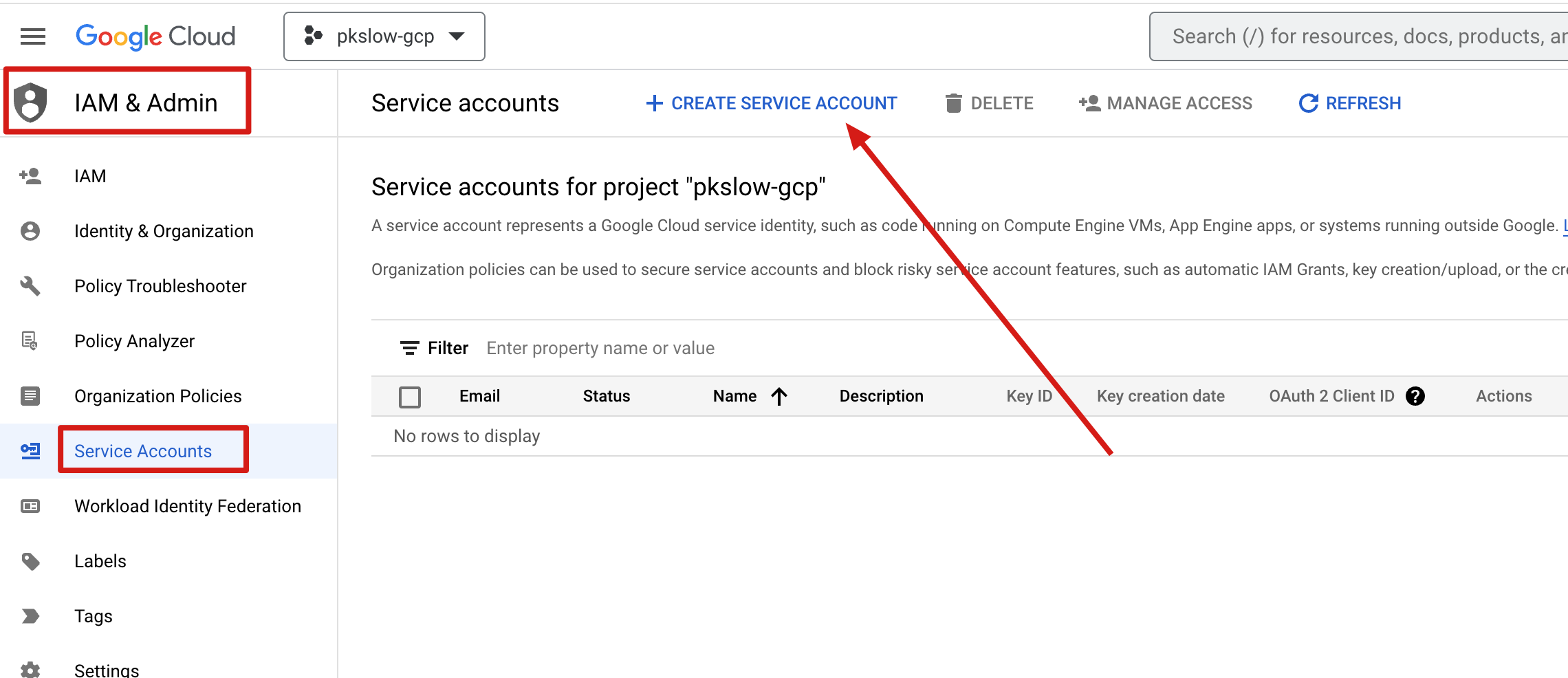
# create a service account
A service account is convenient for authentication:
Input the name and grant Owner Role to the service account:
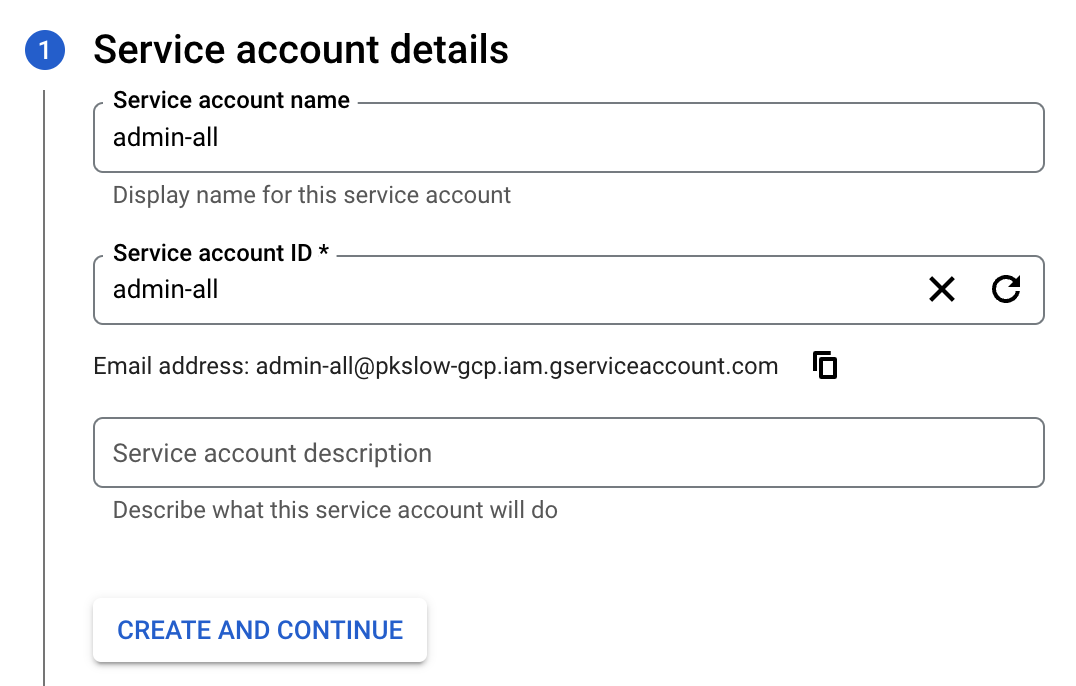
Create a JSON key for the service account, and download the key file:
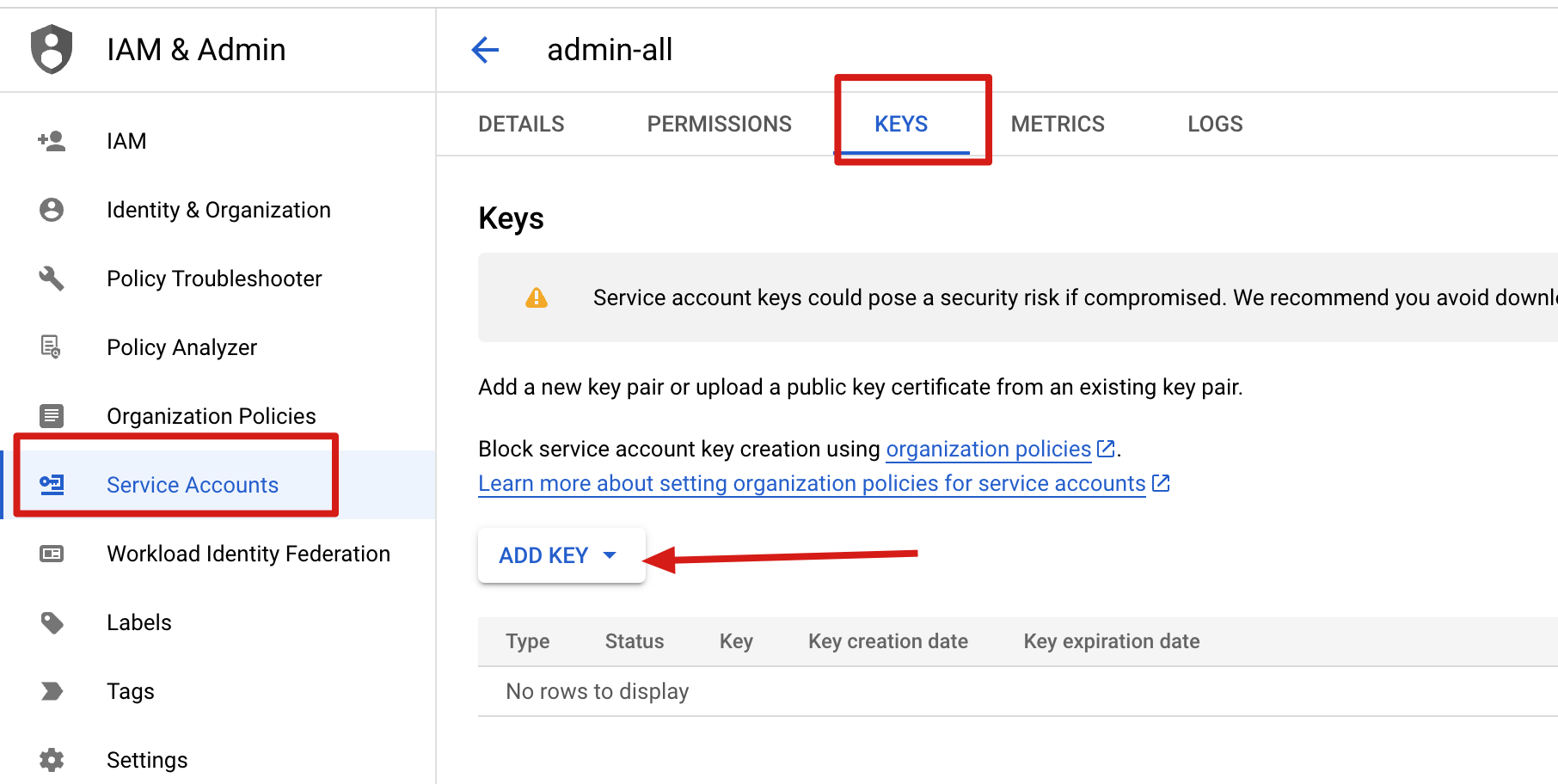
# setup auth for gcloud
Set the env for the credentials:
export GOOGLE_APPLICATION_CREDENTIALS=/Users/larry/Software/google-cloud-sdk/pkslow-gcp-4cdeea1781db.json
Auth for the service account:
$ gcloud auth activate-service-account admin-all@pkslow-gcp.iam.gserviceaccount.com --key-file=${GOOGLE_APPLICATION_CREDENTIALS}
Activated service account credentials for: [admin-all@pkslow-gcp.iam.gserviceaccount.com]
Set the project and check the auth list:
$ gcloud config set project pkslow-gcp
Updated property [core/project].
$ gcloud auth list
Credentialed Accounts
ACTIVE ACCOUNT
* admin-all@pkslow-gcp.iam.gserviceaccount.com
To set the active account, run:
$ gcloud config set account `ACCOUNT`
List the projects:
$ gcloud projects list
PROJECT_ID NAME PROJECT_NUMBER
pkslow-gcp pkslow-gcp 605905500307
# gcloud create vm
Enable the compute service and create the vm:
$ gcloud compute instances create pkslow-vm \
--project=pkslow-gcp \
--zone=us-west1-a \
--machine-type=e2-micro \
--network-interface=network-tier=PREMIUM,subnet=default \
--maintenance-policy=MIGRATE \
--service-account=admin-all@pkslow-gcp.iam.gserviceaccount.com \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--tags=http-server,https-server \
--create-disk=auto-delete=yes,boot=yes,device-name=instance-1,image=projects/centos-cloud/global/images/centos-8-v20211105,mode=rw,size=20,type=projects/pkslow-gcp/zones/us-west1-a/diskTypes/pd-standard \
--no-shielded-secure-boot \
--shielded-vtpm \
--shielded-integrity-monitoring \
--reservation-affinity=any
API [compute.googleapis.com] not enabled on project [605905500307]. Would you like to enable and
retry (this will take a few minutes)? (y/N)? y
Enabling service [compute.googleapis.com] on project [605905500307]...
Operation "operations/acf.p2-605905500307-508eedac-aaf1-4be1-a353-0499eb4ea714" finished successfully.
Created [https://www.googleapis.com/compute/v1/projects/pkslow-gcp/zones/us-west1-a/instances/pkslow-vm].
WARNING: Some requests generated warnings:
- The resource 'projects/centos-cloud/global/images/centos-8-v20211105' is deprecated. A suggested replacement is 'projects/centos-cloud/global/images/centos-8'.
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
pkslow-vm us-west1-a e2-micro 10.138.0.2 34.83.214.176 RUNNING
Check the instances list:
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
pkslow-vm us-west1-a e2-micro 10.138.0.2 34.83.214.176 RUNNING
We can also check on the gcp console:

# Dataflow quick start for python
# Enable related GCP services
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, BigQuery, Cloud Pub/Sub, Cloud Datastore, and Cloud Resource Manager APIs:
gcloud services enable dataflow compute_component logging storage_component storage_api bigquery pubsub datastore.googleapis.com cloudresourcemanager.googleapis.com
# Create a Cloud Storage bucket
gsutil mb -c STANDARD -l US gs://pkslow-gcp-dataflow
# Apache Beam quick start with python
Install python SDK:
pip install apache-beam[gcp]==2.48.0
# Read local file with DirectRunner
Create a python file apache_beam_direct_runner_local.py:
import logging
import re
import apache_beam as beam
def run():
with beam.Pipeline() as pipeline:
print('pipeline start')
result = (pipeline
| 'Read Text' >> beam.io.ReadFromText('/Users/larry/IdeaProjects/pkslow-samples/LICENSE')
| 'ExtractWords' >> beam.FlatMap(lambda x: re.findall(r'[A-Za-z\']+', x))
| 'count' >> beam.combiners.Count.PerElement()
| beam.MapTuple(lambda word, count: '%s: %s' % (word, count))
| beam.io.WriteToText('direct_runner_local_output.txt'))
print(result)
print('pipeline done')
if __name__ == '__main__':
# logging.getLogger().setLevel(logging.INFO)
logging.basicConfig(
format='%(asctime)s %(levelname)-8s %(message)s',
level=logging.INFO,
datefmt='%Y-%m-%d %H:%M:%S')
run()
The application will read a local file and count the words, then write the result to local file.
Run the code:
$ /usr/local/bin/python3.9 apache_beam_direct_runner_local.py
2023-06-18 18:16:45 INFO Missing pipeline option (runner). Executing pipeline using the default runner: DirectRunner.
pipeline start
PCollection[WriteToText/Write/WriteImpl/FinalizeWrite.None]
pipeline done
2023-06-18 18:16:45 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:45 INFO ==================== <function annotate_downstream_side_inputs at 0x12911e550> ====================
2023-06-18 18:16:45 INFO ==================== <function fix_side_input_pcoll_coders at 0x12911e670> ====================
2023-06-18 18:16:45 INFO ==================== <function pack_combiners at 0x12911eb80> ====================
2023-06-18 18:16:45 INFO ==================== <function lift_combiners at 0x12911ec10> ====================
2023-06-18 18:16:45 INFO ==================== <function expand_sdf at 0x12911edc0> ====================
2023-06-18 18:16:45 INFO ==================== <function expand_gbk at 0x12911ee50> ====================
2023-06-18 18:16:45 INFO ==================== <function sink_flattens at 0x12911ef70> ====================
2023-06-18 18:16:45 INFO ==================== <function greedily_fuse at 0x12911f040> ====================
2023-06-18 18:16:46 INFO ==================== <function read_to_impulse at 0x12911f0d0> ====================
2023-06-18 18:16:46 INFO ==================== <function impulse_to_input at 0x12911f160> ====================
2023-06-18 18:16:46 INFO ==================== <function sort_stages at 0x12911f3a0> ====================
2023-06-18 18:16:46 INFO ==================== <function add_impulse_to_dangling_transforms at 0x12911f4c0> ====================
2023-06-18 18:16:46 INFO ==================== <function setup_timer_mapping at 0x12911f310> ====================
2023-06-18 18:16:46 INFO ==================== <function populate_data_channel_coders at 0x12911f430> ====================
2023-06-18 18:16:46 INFO Creating state cache with size 104857600
2023-06-18 18:16:46 INFO Created Worker handler <apache_beam.runners.portability.fn_api_runner.worker_handlers.EmbeddedWorkerHandler object at 0x129391cd0> for environment ref_Environment_default_environment_1 (beam:env:embedded_python:v1, b'')
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
2023-06-18 18:16:46 INFO Starting finalize_write threads with num_shards: 1 (skipped: 0), batches: 1, num_threads: 1
2023-06-18 18:16:46 INFO Renamed 1 shards in 0.02 seconds.
It will generate a result file:
Apache: 4
License: 29
Version: 2
January: 1
http: 2
www: 2
apache: 2
org: 2
# Read gs file with DirectRunner
Create a python file apache_beam_word_count.py the same as example (opens new window).
Run the code:
$ /usr/local/bin/python3.9 apache_beam_word_count.py --output outputs
INFO:root:Missing pipeline option (runner). Executing pipeline using the default runner: DirectRunner.
INFO:apache_beam.internal.gcp.auth:Setting socket default timeout to 60 seconds.
INFO:apache_beam.internal.gcp.auth:socket default timeout is 60.0 seconds.
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function annotate_downstream_side_inputs at 0x1279590d0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function fix_side_input_pcoll_coders at 0x1279591f0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function pack_combiners at 0x127959700> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function lift_combiners at 0x127959790> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function expand_sdf at 0x127959940> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function expand_gbk at 0x1279599d0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sink_flattens at 0x127959af0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function greedily_fuse at 0x127959b80> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function read_to_impulse at 0x127959c10> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function impulse_to_input at 0x127959ca0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sort_stages at 0x127959ee0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function add_impulse_to_dangling_transforms at 0x12795e040> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function setup_timer_mapping at 0x127959e50> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function populate_data_channel_coders at 0x127959f70> ====================
INFO:apache_beam.runners.worker.statecache:Creating state cache with size 104857600
INFO:apache_beam.runners.portability.fn_api_runner.worker_handlers:Created Worker handler <apache_beam.runners.portability.fn_api_runner.worker_handlers.EmbeddedWorkerHandler object at 0x127bcc130> for environment ref_Environment_default_environment_1 (beam:env:embedded_python:v1, b'')
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:apache_beam.io.filebasedsink:Starting finalize_write threads with num_shards: 1 (skipped: 0), batches: 1, num_threads: 1
INFO:apache_beam.io.filebasedsink:Renamed 1 shards in 0.02 seconds.
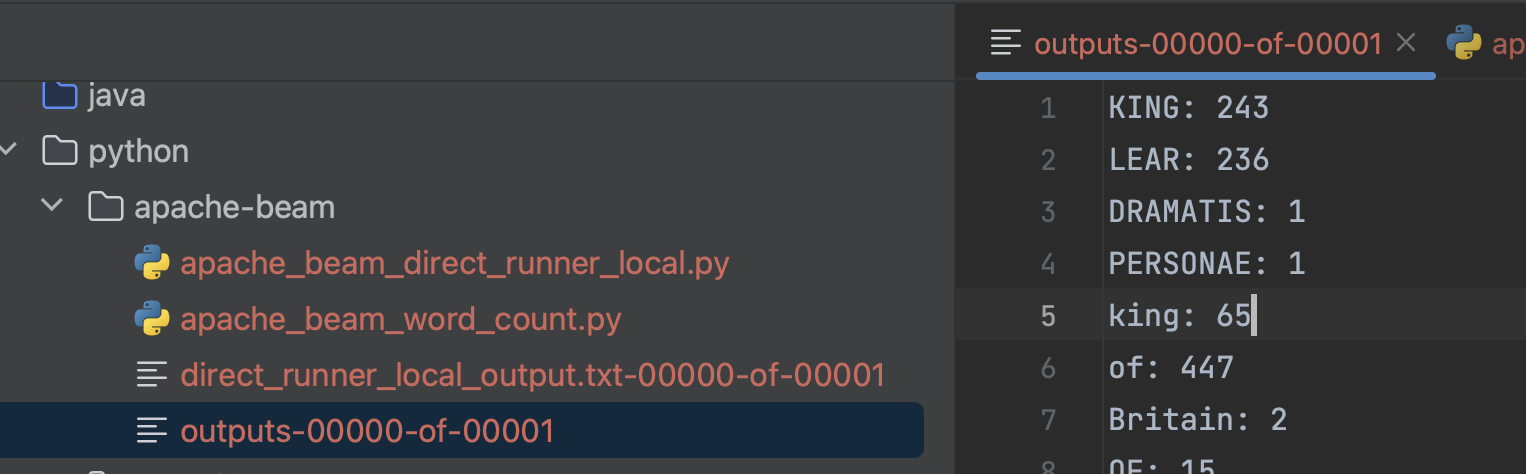
It will generate the result file:
KING: 243
LEAR: 236
DRAMATIS: 1
PERSONAE: 1
king: 65
of: 447
Britain: 2
OF: 15
FRANCE: 10
The source code and output files:
# Run on Dataflow service
/usr/local/bin/python3.9 apache_beam_word_count.py \
--region us-west1 \
--input gs://dataflow-samples/shakespeare/kinglear.txt \
--output gs://pkslow-gcp-dataflow/results/outputs \
--runner DataflowRunner \
--project pkslow-gcp \
--temp_location gs://pkslow-gcp-dataflow/tmp/
The whole execution log:
$ /usr/local/bin/python3.9 apache_beam_word_count.py \
> --region us-west1 \
> --input gs://dataflow-samples/shakespeare/kinglear.txt \
> --output gs://pkslow-gcp-dataflow/results/outputs \
> --runner DataflowRunner \
> --project pkslow-gcp \
> --temp_location gs://pkslow-gcp-dataflow/tmp/
INFO:apache_beam.internal.gcp.auth:Setting socket default timeout to 60 seconds.
INFO:apache_beam.internal.gcp.auth:socket default timeout is 60.0 seconds.
INFO:apache_beam.runners.portability.stager:Downloading source distribution of the SDK from PyPi
INFO:apache_beam.runners.portability.stager:Executing command: ['/usr/local/opt/python@3.9/bin/python3.9', '-m', 'pip', 'download', '--dest', '/var/folders/zl/jrl7_w6n2vx_5t2wtzggntxm0000gn/T/tmp4vp1oih5', 'apache-beam==2.48.0', '--no-deps', '--no-binary', ':all:']
[notice] A new release of pip available: 22.3.1 -> 23.1.2
[notice] To update, run: python3.9 -m pip install --upgrade pip
INFO:apache_beam.runners.portability.stager:Staging SDK sources from PyPI: dataflow_python_sdk.tar
INFO:apache_beam.runners.portability.stager:Downloading binary distribution of the SDK from PyPi
INFO:apache_beam.runners.portability.stager:Executing command: ['/usr/local/opt/python@3.9/bin/python3.9', '-m', 'pip', 'download', '--dest', '/var/folders/zl/jrl7_w6n2vx_5t2wtzggntxm0000gn/T/tmp4vp1oih5', 'apache-beam==2.48.0', '--no-deps', '--only-binary', ':all:', '--python-version', '39', '--implementation', 'cp', '--abi', 'cp39', '--platform', 'manylinux2014_x86_64']
[notice] A new release of pip available: 22.3.1 -> 23.1.2
[notice] To update, run: python3.9 -m pip install --upgrade pip
INFO:apache_beam.runners.portability.stager:Staging binary distribution of the SDK from PyPI: apache_beam-2.48.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
INFO:root:Default Python SDK image for environment is apache/beam_python3.9_sdk:2.48.0
INFO:root:Using provided Python SDK container image: gcr.io/cloud-dataflow/v1beta3/python39:2.48.0
INFO:root:Python SDK container image set to "gcr.io/cloud-dataflow/v1beta3/python39:2.48.0" for Docker environment
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function pack_combiners at 0x11f7168b0> ====================
INFO:apache_beam.runners.portability.fn_api_runner.translations:==================== <function sort_stages at 0x11f7170d0> ====================
INFO:apache_beam.runners.dataflow.internal.apiclient:Defaulting to the temp_location as staging_location: gs://pkslow-gcp-dataflow/tmp/
INFO:apache_beam.runners.dataflow.internal.apiclient:Starting GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/pickled_main_session...
INFO:apache_beam.runners.dataflow.internal.apiclient:Completed GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/pickled_main_session in 1 seconds.
INFO:apache_beam.runners.dataflow.internal.apiclient:Starting GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/dataflow_python_sdk.tar...
INFO:apache_beam.runners.dataflow.internal.apiclient:Completed GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/dataflow_python_sdk.tar in 1 seconds.
INFO:apache_beam.runners.dataflow.internal.apiclient:Starting GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/apache_beam-2.48.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl...
INFO:apache_beam.runners.dataflow.internal.apiclient:Completed GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/apache_beam-2.48.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl in 21 seconds.
INFO:apache_beam.runners.dataflow.internal.apiclient:Starting GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/pipeline.pb...
INFO:apache_beam.runners.dataflow.internal.apiclient:Completed GCS upload to gs://pkslow-gcp-dataflow/tmp/beamapp-larry-0618102713-207274-vsslzg6s.1687084033.207576/pipeline.pb in 0 seconds.
INFO:apache_beam.runners.dataflow.internal.apiclient:Create job: <Job
clientRequestId: '20230618102713208255-2760'
createTime: '2023-06-18T10:27:44.690792Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-18_03_27_42-4147829452393375490'
location: 'us-west1'
name: 'beamapp-larry-0618102713-207274-vsslzg6s'
projectId: 'pkslow-gcp'
stageStates: []
startTime: '2023-06-18T10:27:44.690792Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_BATCH, 1)>
INFO:apache_beam.runners.dataflow.internal.apiclient:Created job with id: [2023-06-18_03_27_42-4147829452393375490]
INFO:apache_beam.runners.dataflow.internal.apiclient:Submitted job: 2023-06-18_03_27_42-4147829452393375490
INFO:apache_beam.runners.dataflow.internal.apiclient:To access the Dataflow monitoring console, please navigate to https://console.cloud.google.com/dataflow/jobs/us-west1/2023-06-18_03_27_42-4147829452393375490?project=pkslow-gcp
INFO:apache_beam.runners.dataflow.dataflow_runner:Job 2023-06-18_03_27_42-4147829452393375490 is in state JOB_STATE_PENDING
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:43.166Z: JOB_MESSAGE_BASIC: Dataflow Runner V2 auto-enabled. Use --experiments=disable_runner_v2 to opt out.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:45.434Z: JOB_MESSAGE_DETAILED: Autoscaling is enabled for job 2023-06-18_03_27_42-4147829452393375490. The number of workers will be between 1 and 1000.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:45.505Z: JOB_MESSAGE_DETAILED: Autoscaling was automatically enabled for job 2023-06-18_03_27_42-4147829452393375490.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.267Z: JOB_MESSAGE_BASIC: Worker configuration: n1-standard-1 in us-west1-a.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.778Z: JOB_MESSAGE_DETAILED: Expanding SplittableParDo operations into optimizable parts.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.808Z: JOB_MESSAGE_DETAILED: Expanding CollectionToSingleton operations into optimizable parts.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.856Z: JOB_MESSAGE_DETAILED: Expanding CoGroupByKey operations into optimizable parts.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.882Z: JOB_MESSAGE_DEBUG: Combiner lifting skipped for step Write/Write/WriteImpl/GroupByKey: GroupByKey not followed by a combiner.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.932Z: JOB_MESSAGE_DETAILED: Expanding GroupByKey operations into optimizable parts.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.955Z: JOB_MESSAGE_DEBUG: Annotating graph with Autotuner information.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:47.981Z: JOB_MESSAGE_DETAILED: Fusing adjacent ParDo, Read, Write, and Flatten operations
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.006Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/InitializeWrite into Write/Write/WriteImpl/DoOnce/Map(decode)
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.026Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/DoOnce/FlatMap(<lambda at core.py:3634>) into Write/Write/WriteImpl/DoOnce/Impulse
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.060Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/DoOnce/Map(decode) into Write/Write/WriteImpl/DoOnce/FlatMap(<lambda at core.py:3634>)
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.086Z: JOB_MESSAGE_DETAILED: Fusing consumer Read/Read/Map(<lambda at iobase.py:908>) into Read/Read/Impulse
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.116Z: JOB_MESSAGE_DETAILED: Fusing consumer ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/PairWithRestriction into Read/Read/Map(<lambda at iobase.py:908>)
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.142Z: JOB_MESSAGE_DETAILED: Fusing consumer ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/SplitWithSizing into ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/PairWithRestriction
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.166Z: JOB_MESSAGE_DETAILED: Fusing consumer Split into ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/ProcessElementAndRestrictionWithSizing
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.192Z: JOB_MESSAGE_DETAILED: Fusing consumer PairWithOne into Split
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.221Z: JOB_MESSAGE_DETAILED: Fusing consumer GroupAndSum/GroupByKey+GroupAndSum/Combine/Partial into PairWithOne
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.247Z: JOB_MESSAGE_DETAILED: Fusing consumer GroupAndSum/GroupByKey/Write into GroupAndSum/GroupByKey+GroupAndSum/Combine/Partial
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.274Z: JOB_MESSAGE_DETAILED: Fusing consumer GroupAndSum/Combine into GroupAndSum/GroupByKey/Read
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.307Z: JOB_MESSAGE_DETAILED: Fusing consumer GroupAndSum/Combine/Extract into GroupAndSum/Combine
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.331Z: JOB_MESSAGE_DETAILED: Fusing consumer Format into GroupAndSum/Combine/Extract
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.353Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/WindowInto(WindowIntoFn) into Format
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.380Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/WriteBundles into Write/Write/WriteImpl/WindowInto(WindowIntoFn)
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.418Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/Pair into Write/Write/WriteImpl/WriteBundles
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.440Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/GroupByKey/Write into Write/Write/WriteImpl/Pair
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.467Z: JOB_MESSAGE_DETAILED: Fusing consumer Write/Write/WriteImpl/Extract into Write/Write/WriteImpl/GroupByKey/Read
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.520Z: JOB_MESSAGE_DEBUG: Workflow config is missing a default resource spec.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.539Z: JOB_MESSAGE_DEBUG: Adding StepResource setup and teardown to workflow graph.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.565Z: JOB_MESSAGE_DEBUG: Adding workflow start and stop steps.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.593Z: JOB_MESSAGE_DEBUG: Assigning stage ids.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.727Z: JOB_MESSAGE_DEBUG: Executing wait step start34
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.781Z: JOB_MESSAGE_BASIC: Executing operation Read/Read/Impulse+Read/Read/Map(<lambda at iobase.py:908>)+ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/PairWithRestriction+ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/SplitWithSizing
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.806Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/DoOnce/Impulse+Write/Write/WriteImpl/DoOnce/FlatMap(<lambda at core.py:3634>)+Write/Write/WriteImpl/DoOnce/Map(decode)+Write/Write/WriteImpl/InitializeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.825Z: JOB_MESSAGE_DEBUG: Starting worker pool setup.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:27:48.846Z: JOB_MESSAGE_BASIC: Starting 1 workers in us-west1-a...
INFO:apache_beam.runners.dataflow.dataflow_runner:Job 2023-06-18_03_27_42-4147829452393375490 is in state JOB_STATE_RUNNING
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:28:39.136Z: JOB_MESSAGE_DETAILED: Autoscaling: Raised the number of workers to 1 based on the rate of progress in the currently running stage(s).
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:29:05.873Z: JOB_MESSAGE_DETAILED: Workers have started successfully.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:32.740Z: JOB_MESSAGE_DETAILED: All workers have finished the startup processes and began to receive work requests.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.737Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/DoOnce/Impulse+Write/Write/WriteImpl/DoOnce/FlatMap(<lambda at core.py:3634>)+Write/Write/WriteImpl/DoOnce/Map(decode)+Write/Write/WriteImpl/InitializeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.801Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/DoOnce/Map(decode).None" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.830Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/InitializeWrite.None" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.887Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/WriteBundles/View-python_side_input0-Write/Write/WriteImpl/WriteBundles
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.921Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input0-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.953Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/WriteBundles/View-python_side_input0-Write/Write/WriteImpl/WriteBundles
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.960Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/PreFinalize/View-python_side_input0-Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:34.972Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input0-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.005Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/PreFinalize/View-python_side_input0-Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.012Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/WriteBundles/View-python_side_input0-Write/Write/WriteImpl/WriteBundles.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.037Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/FinalizeWrite/View-python_side_input0-Write/Write/WriteImpl/FinalizeWrite.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.064Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/PreFinalize/View-python_side_input0-Write/Write/WriteImpl/PreFinalize.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.621Z: JOB_MESSAGE_BASIC: Finished operation Read/Read/Impulse+Read/Read/Map(<lambda at iobase.py:908>)+ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/PairWithRestriction+ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/SplitWithSizing
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.676Z: JOB_MESSAGE_DEBUG: Value "ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7-split-with-sizing-out3" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:35.742Z: JOB_MESSAGE_BASIC: Executing operation GroupAndSum/GroupByKey/Create
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:36.156Z: JOB_MESSAGE_BASIC: Finished operation GroupAndSum/GroupByKey/Create
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:36.216Z: JOB_MESSAGE_DEBUG: Value "GroupAndSum/GroupByKey/Session" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:36.279Z: JOB_MESSAGE_BASIC: Executing operation ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/ProcessElementAndRestrictionWithSizing+Split+PairWithOne+GroupAndSum/GroupByKey+GroupAndSum/Combine/Partial+GroupAndSum/GroupByKey/Write
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:37.999Z: JOB_MESSAGE_BASIC: Finished operation ref_AppliedPTransform_Read-Read-SDFBoundedSourceReader-ParDo-SDFBoundedSourceDoFn-_7/ProcessElementAndRestrictionWithSizing+Split+PairWithOne+GroupAndSum/GroupByKey+GroupAndSum/Combine/Partial+GroupAndSum/GroupByKey/Write
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.054Z: JOB_MESSAGE_BASIC: Executing operation GroupAndSum/GroupByKey/Close
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.112Z: JOB_MESSAGE_BASIC: Finished operation GroupAndSum/GroupByKey/Close
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.175Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/GroupByKey/Create
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.290Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/GroupByKey/Create
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.349Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/GroupByKey/Session" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:38.404Z: JOB_MESSAGE_BASIC: Executing operation GroupAndSum/GroupByKey/Read+GroupAndSum/Combine+GroupAndSum/Combine/Extract+Format+Write/Write/WriteImpl/WindowInto(WindowIntoFn)+Write/Write/WriteImpl/WriteBundles+Write/Write/WriteImpl/Pair+Write/Write/WriteImpl/GroupByKey/Write
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:39.502Z: JOB_MESSAGE_BASIC: Finished operation GroupAndSum/GroupByKey/Read+GroupAndSum/Combine+GroupAndSum/Combine/Extract+Format+Write/Write/WriteImpl/WindowInto(WindowIntoFn)+Write/Write/WriteImpl/WriteBundles+Write/Write/WriteImpl/Pair+Write/Write/WriteImpl/GroupByKey/Write
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:39.558Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/GroupByKey/Close
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:39.612Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/GroupByKey/Close
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:39.660Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/GroupByKey/Read+Write/Write/WriteImpl/Extract
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:41.917Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/GroupByKey/Read+Write/Write/WriteImpl/Extract
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:41.967Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/Extract.None" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.013Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input1-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.036Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/PreFinalize/View-python_side_input1-Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.059Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input1-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.115Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/FinalizeWrite/View-python_side_input1-Write/Write/WriteImpl/FinalizeWrite.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.141Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/PreFinalize/View-python_side_input1-Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.196Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/PreFinalize/View-python_side_input1-Write/Write/WriteImpl/PreFinalize.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:42.246Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:44.921Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/PreFinalize
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:44.978Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/PreFinalize.None" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:45.031Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input2-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:45.083Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/FinalizeWrite/View-python_side_input2-Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:45.132Z: JOB_MESSAGE_DEBUG: Value "Write/Write/WriteImpl/FinalizeWrite/View-python_side_input2-Write/Write/WriteImpl/FinalizeWrite.out" materialized.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:45.185Z: JOB_MESSAGE_BASIC: Executing operation Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:46.669Z: JOB_MESSAGE_BASIC: Finished operation Write/Write/WriteImpl/FinalizeWrite
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:46.718Z: JOB_MESSAGE_DEBUG: Executing success step success32
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:46.780Z: JOB_MESSAGE_DETAILED: Cleaning up.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:47.056Z: JOB_MESSAGE_DEBUG: Starting worker pool teardown.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:30:47.079Z: JOB_MESSAGE_BASIC: Stopping worker pool...
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:31:30.978Z: JOB_MESSAGE_DETAILED: Autoscaling: Resized worker pool from 1 to 0.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:31:31.014Z: JOB_MESSAGE_BASIC: Worker pool stopped.
INFO:apache_beam.runners.dataflow.dataflow_runner:2023-06-18T10:31:31.041Z: JOB_MESSAGE_DEBUG: Tearing down pending resources...
INFO:apache_beam.runners.dataflow.dataflow_runner:Job 2023-06-18_03_27_42-4147829452393375490 is in state JOB_STATE_DONE
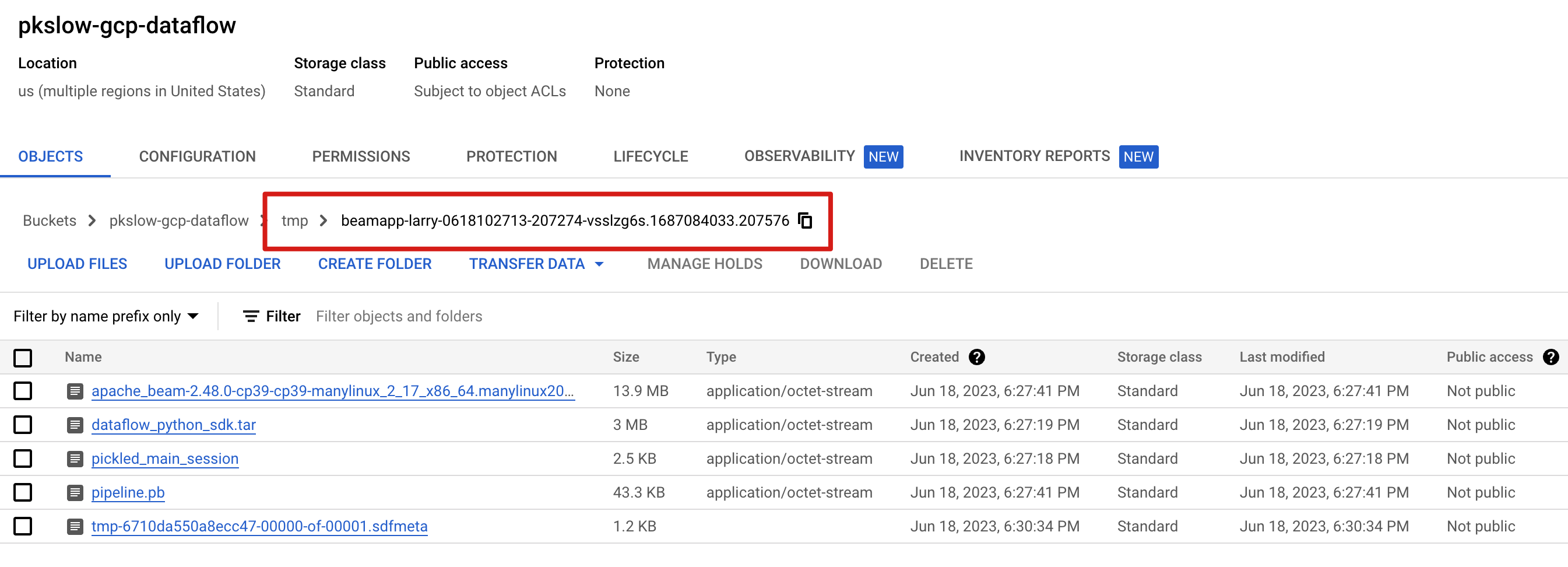
It uploaded the package to the temp folder on GS, and then it created a Dataflow job to execute.
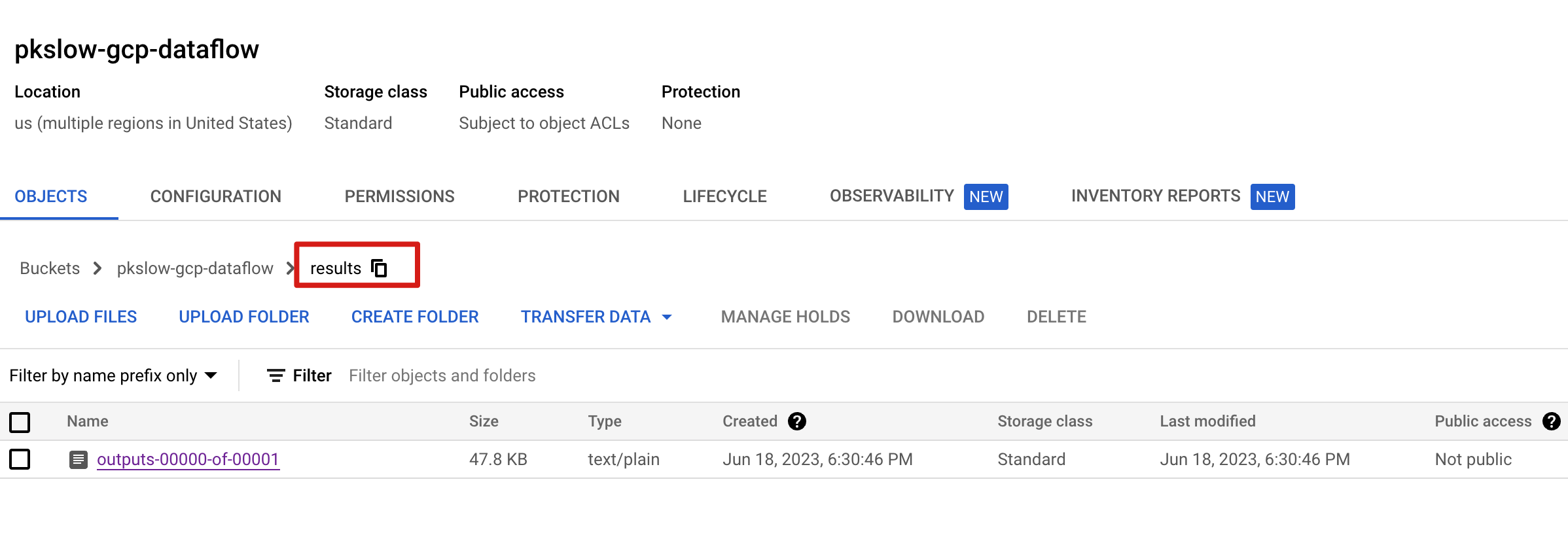
It wrote the final result to the GS folder.

The code on pkslow-samples/python/apache-beam (opens new window)
References:
GCP Dataflow Apache Beam with Python (opens new window)
Understanding the Dataflow Quickstart for Python Tutorial (opens new window)
Explain Apache Beam python syntax (opens new window)
Print timestamp for logging in Python (opens new window)
Where does PIP Store / Save Python 3 Modules / Packages on Windows 8? (opens new window)
# Dataproc on GCP
We can create Dataproc on GCE or GKE, now let create on GCE for quickstart.
Input the name and the location:
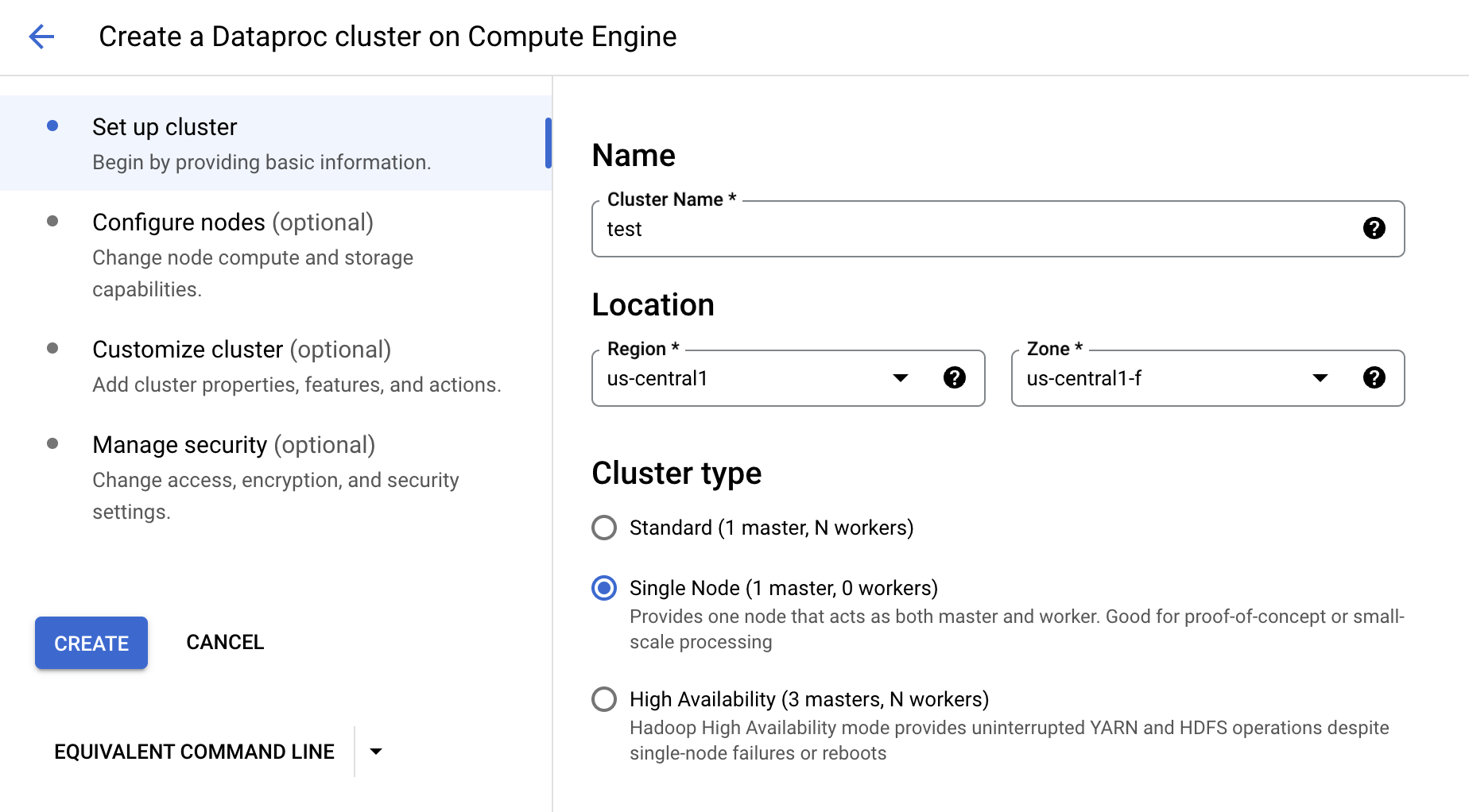
We can also configure the node type. After all the parameters configured, click CREATE.
# run python on spark locally
Firstly, we need to install the pyspark:
$ pip install pyspark
Verify the lib:
$ pip show pyspark
Name: pyspark
Version: 3.4.0
Summary: Apache Spark Python API
Home-page: https://github.com/apache/spark/tree/master/python
Author: Spark Developers
Author-email: dev@spark.apache.org
License: http://www.apache.org/licenses/LICENSE-2.0
Location: /usr/local/lib/python3.9/site-packages
Requires: py4j
Required-by:
Write a simple wordcount code:
import sys
from pyspark.sql import SparkSession
from operator import add
import os
def run_spark(filename):
spark = SparkSession.builder.appName('pkslow-local').getOrCreate()
lines = spark.read.text(filename).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
output.sort(key=lambda item: item[1])
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()
if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage: wordcount <file>", file=sys.stderr)
sys.exit(-1)
os.environ['PYSPARK_PYTHON'] = '/usr/local/bin/python3.9'
filename = sys.argv[1]
run_spark(filename)
Run the code:
$ python3.9 spark_local.py /Users/larry/IdeaProjects/pkslow-samples/LICENSE
# issue: python in worker has different version 3.10 than that in driver 3.9
Set the env PYSPARK_PYTHON:
os.environ['PYSPARK_PYTHON'] = '/usr/local/bin/python3.9'
Or can set the system env before you run the code.
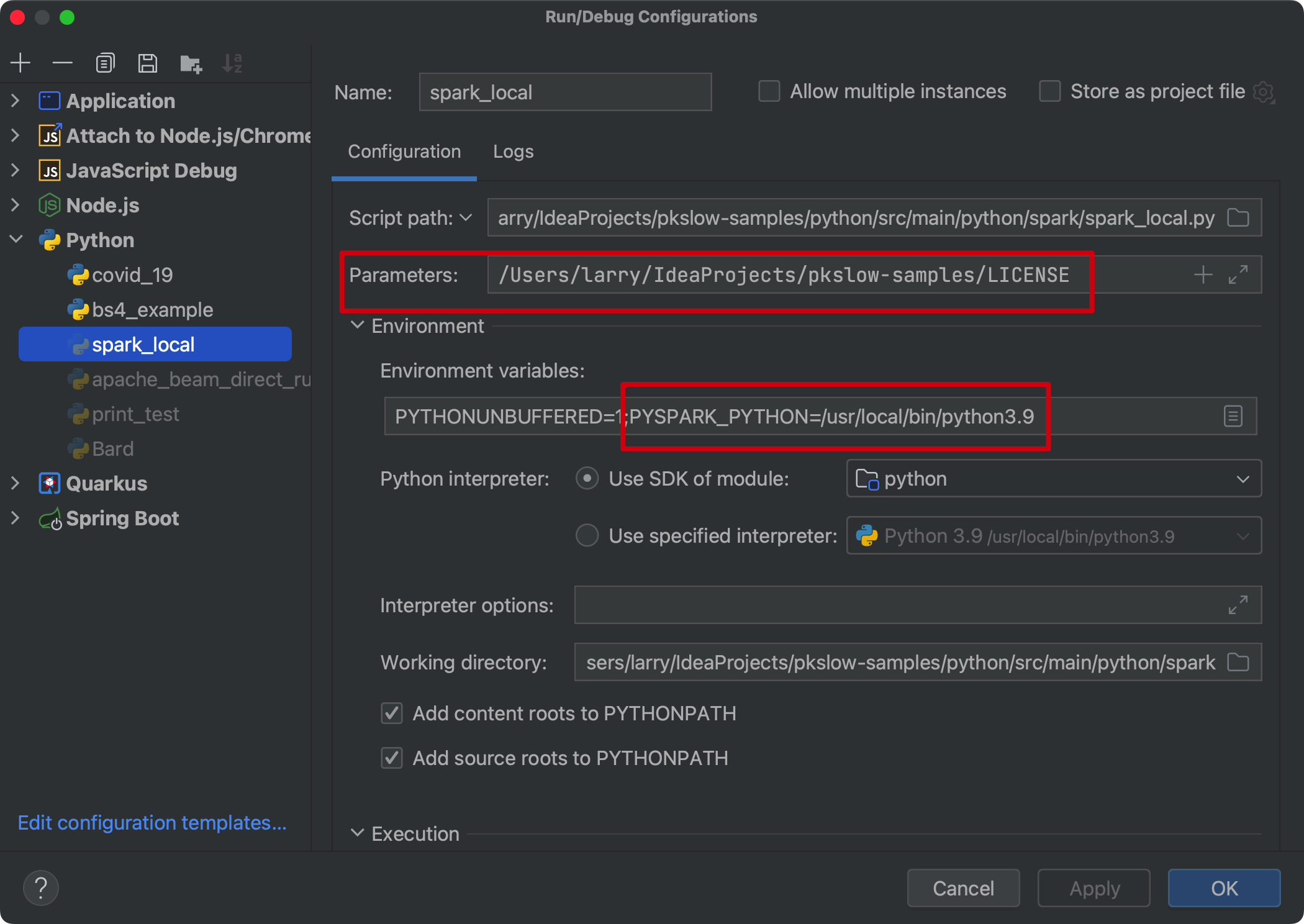
# Submit Python job to Dataproc
Create a python file spark_gs.py:
#!/usr/bin/env python
import pyspark
import sys
if len(sys.argv) != 3:
raise Exception("Exactly 2 arguments are required: <inputUri> <outputUri>")
inputUri = sys.argv[1]
outputUri = sys.argv[2]
sc = pyspark.SparkContext()
lines = sc.textFile(sys.argv[1])
words = lines.flatMap(lambda line: line.split())
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda count1, count2: count1 + count2)
wordCounts.saveAsTextFile(sys.argv[2])
Submit the jobs with gcloud command:
$ gcloud dataproc jobs submit pyspark spark_gs.py --cluster=test --region=us-central1 -- gs://dataflow-samples/shakespeare/kinglear.txt gs://pkslow-gcp-dataproc/result/
Job [89ea141a0d764c5eae2874f9912061ee] submitted.
Waiting for job output...
23/06/24 03:38:41 INFO org.apache.spark.SparkEnv: Registering MapOutputTracker
23/06/24 03:38:41 INFO org.apache.spark.SparkEnv: Registering BlockManagerMaster
23/06/24 03:38:41 INFO org.apache.spark.SparkEnv: Registering BlockManagerMasterHeartbeat
23/06/24 03:38:41 INFO org.apache.spark.SparkEnv: Registering OutputCommitCoordinator
23/06/24 03:38:41 INFO org.sparkproject.jetty.util.log: Logging initialized @3650ms to org.sparkproject.jetty.util.log.Slf4jLog
23/06/24 03:38:41 INFO org.sparkproject.jetty.server.Server: jetty-9.4.40.v20210413; built: 2021-04-13T20:42:42.668Z; git: b881a572662e1943a14ae12e7e1207989f218b74; jvm 1.8.0_372-b07
23/06/24 03:38:41 INFO org.sparkproject.jetty.server.Server: Started @3801ms
23/06/24 03:38:41 INFO org.sparkproject.jetty.server.AbstractConnector: Started ServerConnector@7dfb5455{HTTP/1.1, (http/1.1)}{0.0.0.0:41809}
23/06/24 03:38:42 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at test-m/10.128.0.8:8032
23/06/24 03:38:42 INFO org.apache.hadoop.yarn.client.AHSProxy: Connecting to Application History server at test-m/10.128.0.8:10200
23/06/24 03:38:44 INFO org.apache.hadoop.conf.Configuration: resource-types.xml not found
23/06/24 03:38:44 INFO org.apache.hadoop.yarn.util.resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/06/24 03:38:45 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: Submitted application application_1687337392105_0002
23/06/24 03:38:46 INFO org.apache.hadoop.yarn.client.RMProxy: Connecting to ResourceManager at test-m/10.128.0.8:8030
23/06/24 03:38:49 INFO com.google.cloud.hadoop.repackaged.gcs.com.google.cloud.hadoop.gcsio.GoogleCloudStorageImpl: Ignoring exception of type GoogleJsonResponseException; verified object already exists with desired state.
23/06/24 03:38:53 INFO org.apache.hadoop.mapred.FileInputFormat: Total input files to process : 1
23/06/24 03:39:12 INFO com.google.cloud.hadoop.repackaged.gcs.com.google.cloud.hadoop.gcsio.GoogleCloudStorageFileSystem: Successfully repaired 'gs://pkslow-gcp-dataproc/result/' directory.
23/06/24 03:39:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped Spark@7dfb5455{HTTP/1.1, (http/1.1)}{0.0.0.0:0}
Job [89ea141a0d764c5eae2874f9912061ee] finished successfully.
done: true
driverControlFilesUri: gs://dataproc-staging-us-central1-605905500307-bt2ibh6v/google-cloud-dataproc-metainfo/1ceb8e02-6124-498b-97ac-24f6ec27ed95/jobs/89ea141a0d764c5eae2874f9912061ee/
driverOutputResourceUri: gs://dataproc-staging-us-central1-605905500307-bt2ibh6v/google-cloud-dataproc-metainfo/1ceb8e02-6124-498b-97ac-24f6ec27ed95/jobs/89ea141a0d764c5eae2874f9912061ee/driveroutput
jobUuid: ea41c320-7196-32c1-ac04-f500924bf8a3
placement:
clusterName: test
clusterUuid: 1ceb8e02-6124-498b-97ac-24f6ec27ed95
pysparkJob:
args:
- gs://dataflow-samples/shakespeare/kinglear.txt
- gs://pkslow-gcp-dataproc/result/
mainPythonFileUri: gs://dataproc-staging-us-central1-605905500307-bt2ibh6v/google-cloud-dataproc-metainfo/1ceb8e02-6124-498b-97ac-24f6ec27ed95/jobs/89ea141a0d764c5eae2874f9912061ee/staging/spark_gs.py
reference:
jobId: 89ea141a0d764c5eae2874f9912061ee
projectId: pkslow-gcp
status:
state: DONE
stateStartTime: '2023-06-24T03:39:17.489713Z'
statusHistory:
- state: PENDING
stateStartTime: '2023-06-24T03:38:36.302890Z'
- state: SETUP_DONE
stateStartTime: '2023-06-24T03:38:36.358310Z'
- details: Agent reported job success
state: RUNNING
stateStartTime: '2023-06-24T03:38:36.579046Z'
yarnApplications:
- name: spark_gs.py
progress: 1.0
state: FINISHED
trackingUrl: http://test-m:8088/proxy/application_1687337392105_0002/
After the jobs is completed, check the result:
$ gsutil ls gs://pkslow-gcp-dataproc/result
gs://pkslow-gcp-dataproc/result/
gs://pkslow-gcp-dataproc/result/_SUCCESS
gs://pkslow-gcp-dataproc/result/part-00000
gs://pkslow-gcp-dataproc/result/part-00001
$ gsutil cat gs://pkslow-gcp-dataproc/result/part-00000
('LEAR', 222)
('PERSONAE', 1)
('king', 29)
('of', 439)
('(KING', 1)
('OF', 15)
('FRANCE:', 1)
('DUKE', 3)
('(BURGUNDY:)', 1)
('(CORNWALL:)', 1)
('(KENT:)', 1)
('(GLOUCESTER:)', 1)
('son', 21)
('Gloucester.', 9)
('bastard', 4)
('CURAN', 6)
('courtier.', 1)
...
We can also check the execution details on console:
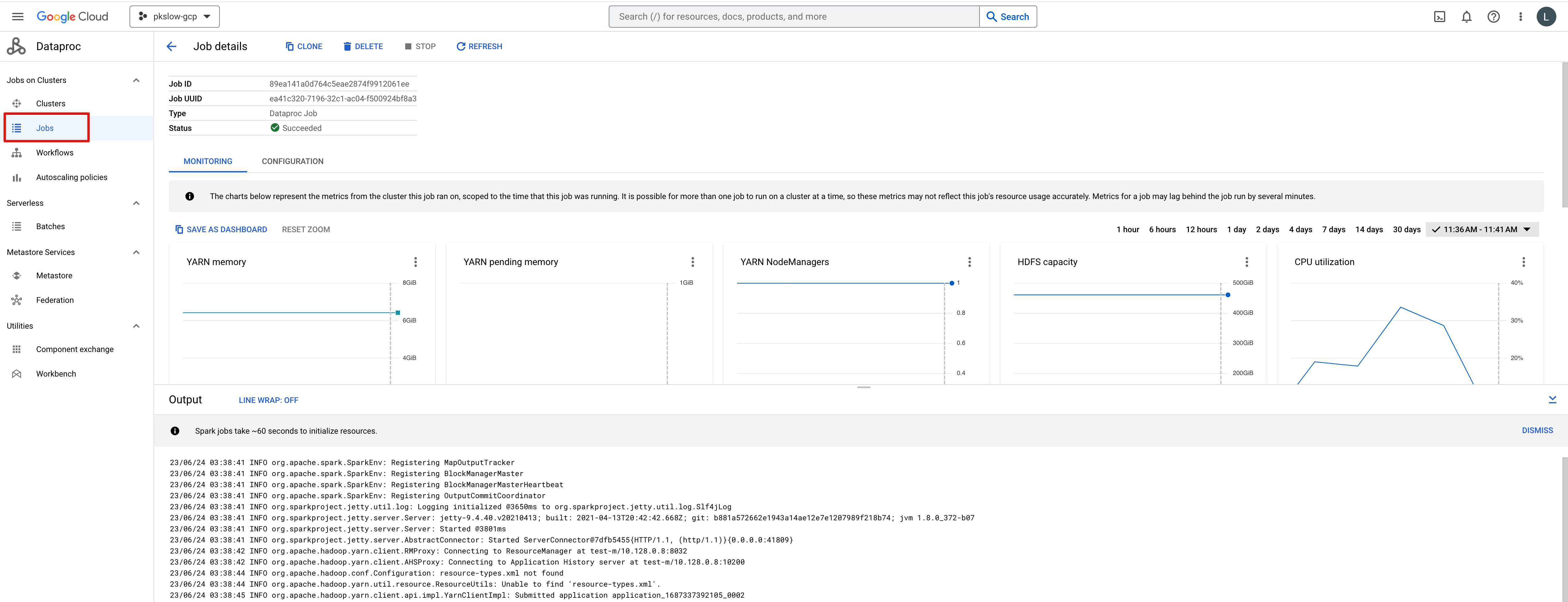
References:
Use the Cloud Storage connectot with Spark (opens new window)
# Airflow on GCP (Cloud Composer)
Cloud Composer is a fully managed Apache Airflow service on GCP. It empowers us to author, schedule and monitor pipelines.
# Create Composer 2
I created a Composer service with small resources:
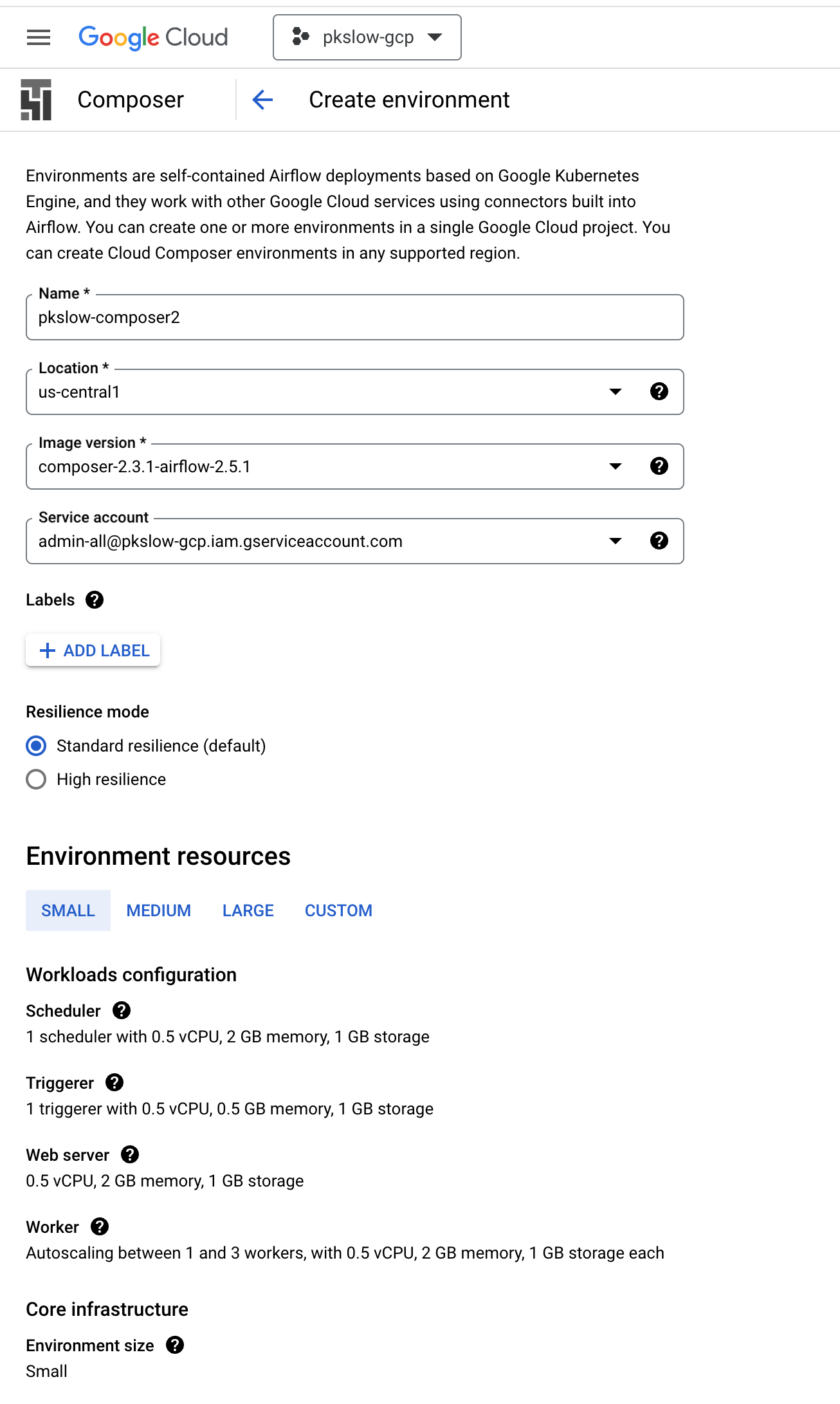
In fact, it's running on GKE with Autopilot mode:
$ gcloud container clusters list
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
us-central1-pkslow-composer-d7602fc1-gke us-central1 1.25.8-gke.1000 35.225.201.14 e2-medium 1.25.8-gke.1000 3 RUNNING
We can open the Airflow UI and open the DAGs folder in the console:

Airflow UI: https://cc713e0579414acf973265adfedb5e86-dot-us-central1.composer.googleusercontent.com/home

The DAGs:

# Create and submit DAGs
Install the Python airflow package:
$ pip install apache-airflow
Write the code for DAG:
from datetime import datetime
from airflow import DAG
from airflow.models.baseoperator import chain
from airflow.operators.bash import BashOperator
from airflow.operators.empty import EmptyOperator
from airflow.operators.python import PythonOperator
dag_test = DAG(
dag_id="pkslow_test_dag",
start_date=datetime(2023, 6, 13, 5, 12, 0),
schedule_interval='*/10 * * * *',
)
generate_random_number = BashOperator(
task_id="generate_random_number",
bash_command='echo $RANDOM',
dag=dag_test,
)
def print_message():
print("This is a Python Operator by www.pkslow.com.")
python_task = PythonOperator(
task_id="print_message",
python_callable=print_message,
dag=dag_test
)
t0 = EmptyOperator(task_id="t0")
t1 = EmptyOperator(task_id="t1")
t2 = EmptyOperator(task_id="t2")
t3 = EmptyOperator(task_id="t3")
t4 = EmptyOperator(task_id="t4")
t5 = EmptyOperator(task_id="t5")
t6 = EmptyOperator(task_id="t6")
chain(generate_random_number, python_task, t0, t1, [t2, t3], [t4, t5], t6)
Submit the DAG to the GS with gsutil:
$ gsutil cp bash_python_operator.py gs://us-central1-pkslow-composer-d7602fc1-bucket/dags/
Copying file://bash_python_operator.py [Content-Type=text/x-python]...
/ [1 files][ 920.0 B/ 920.0 B]
Operation completed over 1 objects/920.0 B.
It will be automatically detected and rendered:

References: Manage DAG and task dependencies in Airflow (opens new window)
# airflow + dataflow
Install the Apache Beam package for airflow:
pip install apache-airflow-providers-apache-beam[google]
Define the DAG:
from airflow import DAG
import airflow
from datetime import timedelta
from airflow.providers.apache.beam.operators.beam import BeamRunPythonPipelineOperator
default_args = {
'owner': 'Airflow',
# 'start_date':airflow.utils.dates.days_ago(1),
'retries': 1,
'retry_delay': timedelta(seconds=50),
'dataflow_default_options': {
'project': 'pkslow-gcp',
'region': 'us-west1',
'runner': 'DataflowRunner'
}
}
dag = DAG(
dag_id='pkslow_dataflow',
default_args=default_args,
schedule_interval='@daily',
start_date=airflow.utils.dates.days_ago(1),
catchup=False,
description="DAG for data ingestion and transformation"
)
dataflow_task = BeamRunPythonPipelineOperator(
task_id='pkslow_dataflow_job',
py_file='gs://us-central1-pkslow-composer-d7602fc1-bucket/py_scripts/apache_beam_word_count.py',
runner='DataFlowRunner',
pipeline_options={
'input': 'gs://dataflow-samples/shakespeare/kinglear.txt',
'output': 'gs://pkslow-gcp-dataflow/results/outputs',
'temp_location': 'gs://pkslow-gcp-dataflow/tmp/',
},
dag=dag
)
The Python script apache_beam_word_count.py is here: Dataflow on GCP (opens new window). And we need to pass the parameter as pipeline_options.
Upload the Python script:
$ gsutil cp apache-beam/apache_beam_word_count.py gs://us-central1-pkslow-composer-d7602fc1-bucket/py_scripts/
Upload the DAG:
$ gsutil cp airflow_dataflow.py gs://us-central1-pkslow-composer-d7602fc1-bucket/dags/
After a while, check on the Airflow UI:
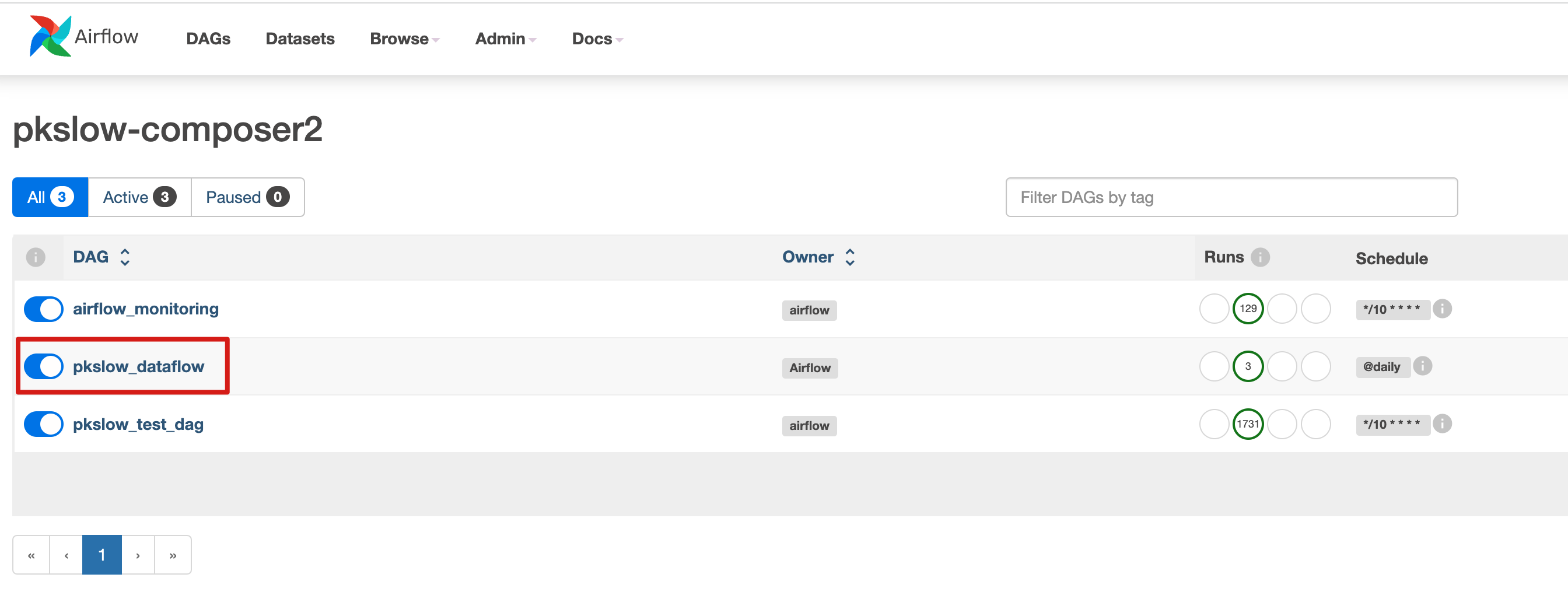
Trigger the job and check the log and result:

Result:

References:
Google Cloud Dataflow Operators (opens new window)
Launching Dataflow pipelines with Cloud Composer (opens new window)
Vignesh Cloud Composer (opens new window)
# airflow+dataproc
Define DAG:
import airflow
from airflow import DAG
from airflow.providers.google.cloud.operators.dataproc import DataprocSubmitJobOperator
PROJECT_ID = "pkslow-gcp"
CLUSTER_NAME = 'test'
REGION = 'us-central1'
PYSPARK_URI = f'gs://pkslow-gcp-dataproc/python-scripts/spark_gs.py'
PYSPARK_JOB = {
"reference": {"project_id": PROJECT_ID},
"placement": {"cluster_name": CLUSTER_NAME},
"pyspark_job": {"main_python_file_uri": PYSPARK_URI, "args": [
'gs://dataflow-samples/shakespeare/kinglear.txt', 'gs://pkslow-gcp-dataproc/result/'
]},
}
dag = DAG(
dag_id='pkslow_dataproc',
schedule_interval='@daily',
start_date=airflow.utils.dates.days_ago(1),
catchup=False,
description="DAG for data ingestion and transformation"
)
pyspark_task = DataprocSubmitJobOperator(
task_id="pkslow_pyspark_task",
job=PYSPARK_JOB,
region=REGION,
project_id=PROJECT_ID,
dag=dag
)
Upload python script:
$ gsutil cp spark/spark_gs.py gs://pkslow-gcp-dataproc/python-scripts/
Copying file://spark/spark_gs.py [Content-Type=text/x-python]...
/ [1 files][ 550.0 B/ 550.0 B]
Operation completed over 1 objects/550.0 B.
Upload DAG:
$ gsutil cp airflow/airflow_dataproc.py gs://us-central1-pkslow-composer-d7602fc1-bucket/dags/
Copying file://airflow/airflow_dataproc.py [Content-Type=text/x-python]...
/ [1 files][ 1015 B/ 1015 B]
Operation completed over 1 objects/1015.0 B.
Trigger the job:
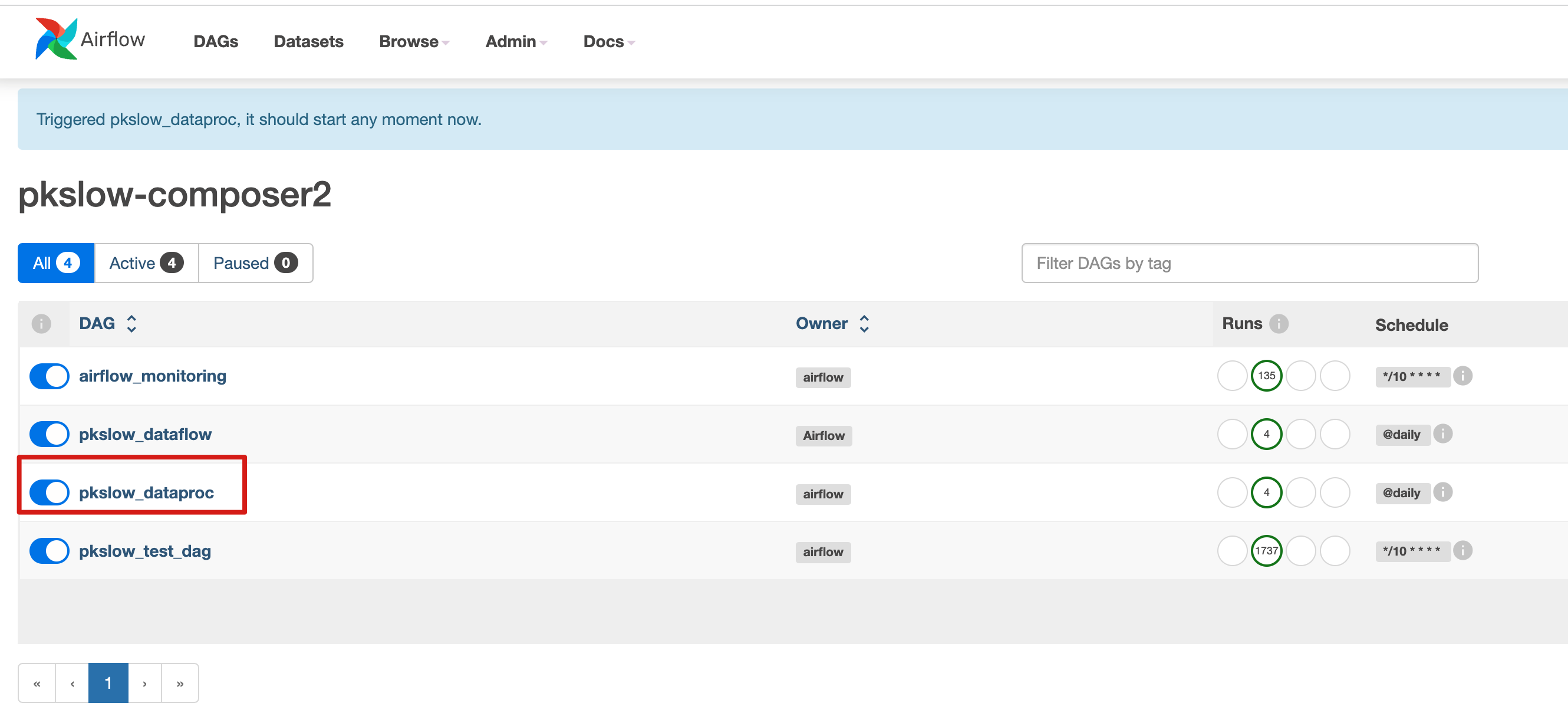
Check the result:
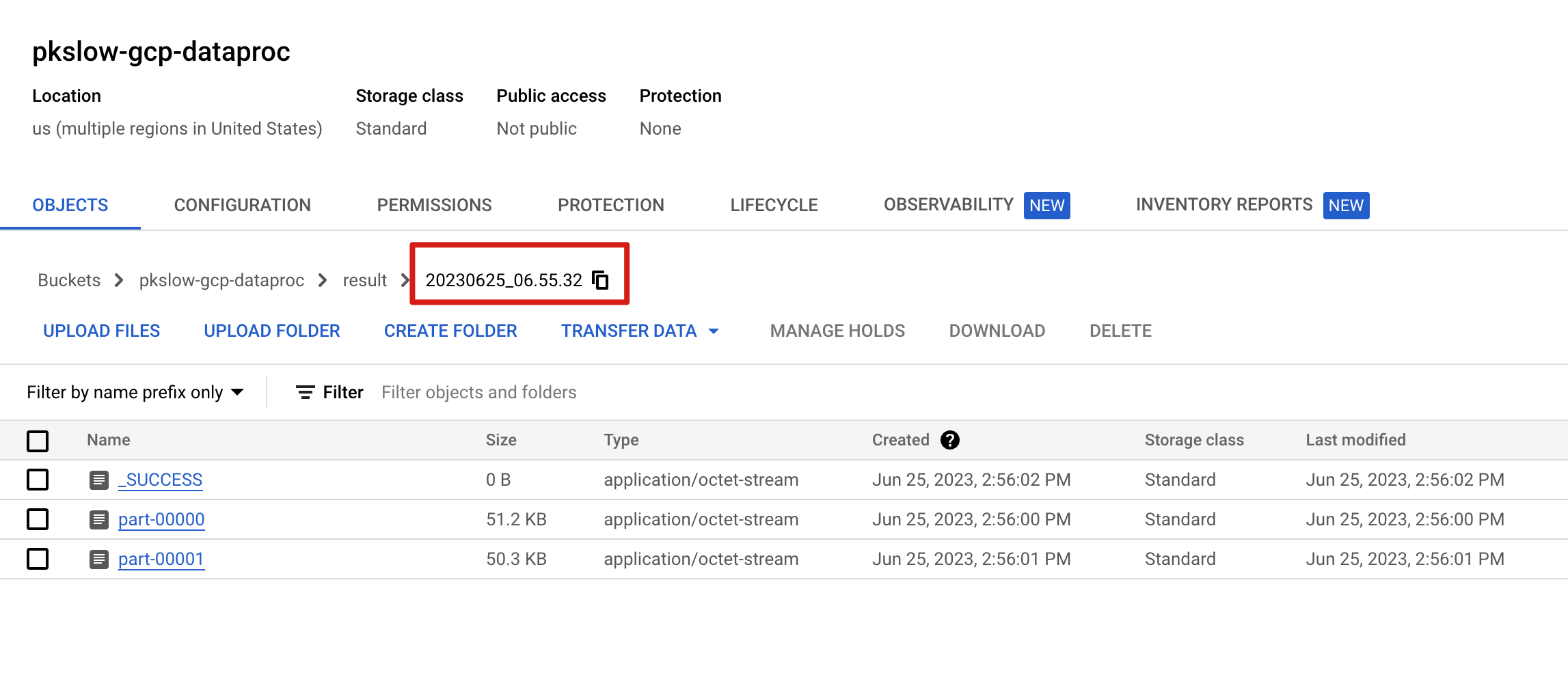
Can check the execution details on Dataproc:
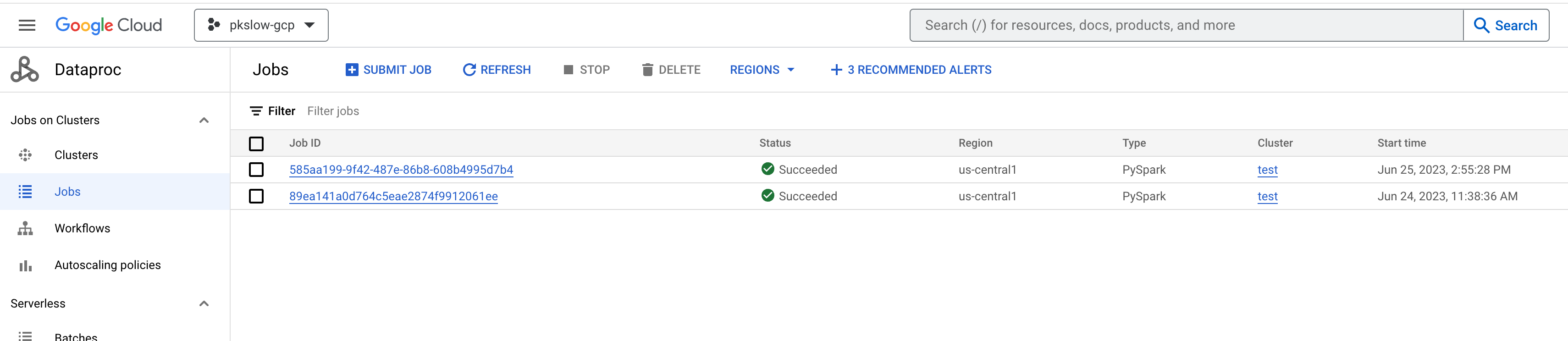
References:
Google Cloud Dataproc Operators (opens new window)
Dataproc PySpark Job Docs (opens new window)
Data lake with Pyspark through Dataproc GCP using Airflow (opens new window)